MongoDB가 트랜잭션을 보장하는 방법
개요
지난 글에서 이어지는 글이지만 읽지 않아도 무방합니다.
NoSQL이라는 용어때문에 헷갈릴 수 있는데 Non-SQL, Not Only SQL 이 두 정의로 나눠져서 명확한 정의는 없지만, 후자의 설명을 따르자면 데이터 저장 시 SQL 외에도 다른 방법으로 저장할 수 있다는 의미를 나타내기도 합니다.
다소 폭력적인(?) 어감때문에 처음에는 MongoDB가 트랜잭션을 지원하지 않는 줄 알았는데 Document 형태로 저장될 뿐 트랜잭션을 지원합니다.
MongoDB가 어떻게 트랜잭션을 지원하는지 알아보겠습니다.
Standalone 단일 도큐먼트
먼저 StandAlone(노드가 하나일 때) 환경에서는 단일 도큐먼트(single-document level)에 한해 write operation이 원자성을 보장합니다.
이 때 원자성을 보장해주는 것은 MongoDB의 기본 스토리지 엔진인 WiredTiger입니다.
문서 수준 동시성
WiredTiger는 write 작업에 대해 document-level concurrency control을 제공합니다.
global, database, collection 수준에서는 intent lock(의도 락)을 사용하고, 실제 더 세밀한 충돌 조정은 WiredTiger가 담당합니다.
또한 WiredTiger는 대부분의 read/write에서 optimistic concurrency control을 사용하는데, 두 요청이 같은 도큐먼트를 동시에 수정하려다가 충돌하면 한쪽에서 write conflict가 발생하고, 일부 단일 write를 재시도합니다.
코드로 보면:
db.orders.insertMany([
{ _id: "order-1", reservedQuantity: 0 },
{ _id: "order-2", reservedQuantity: 0 }
])여기서는 orders 컬렉션에 위처럼 서로 다른 두 도큐먼트가 이미 있다고 가정합니다.
MongoDB는 컬렉션마다 _id에 unique index를 만들기 때문에, 같은 컬렉션 안에서 _id: "order-1"과 _id: "order-2"는 같은 도큐먼트를 가리킬 수 없습니다.
이 상태에서 아래 두 요청이 들어옵니다.
// 요청 A
db.orders.updateOne(
{ _id: "order-1" },
{ $inc: { reservedQuantity: 1 } }
)
// 요청 B
db.orders.updateOne(
{ _id: "order-2" },
{ $inc: { reservedQuantity: 1 } }
)위 두 요청은 둘 다 orders 컬렉션을 수정하지만, 검색 조건이 서로 다른 _id를 지정하므로 대상 도큐먼트가 다릅니다. 만약 해당 _id를 가진 도큐먼트가 없다면 그 요청은 아무 도큐먼트도 수정하지 않습니다.
MongoDB 입장에서는 둘 다 orders 컬렉션에 쓰기 작업을 하겠다는 상위 레벨의 intent lock을 둡니다.
하지만 실제 변경 대상은 order-1, order-2로 나뉘기 때문에 WiredTiger는 두 write를 같은 도큐먼트 경합으로 보지 않습니다.
반대로 같은 도큐먼트를 동시에 바꾸면 충돌 가능성이 생깁니다. 예를 들어 남은 객실이 1개인 재고 도큐먼트가 있다고 해보겠습니다.
db.room_inventory.insertOne({
_id: "room-type-1:2026-05-01",
remaining: 1
})이때 두 요청이 거의 동시에 아래 update를 실행합니다.
db.room_inventory.updateOne(
{
_id: "room-type-1:2026-05-01",
remaining: { $gt: 0 }
},
{
$inc: { remaining: -1 }
}
)remaining > 0 조건 확인과 $inc 적용이 하나의 단일 도큐먼트 write 안에서 처리됩니다.
그래서 둘 중 하나가 먼저 성공해 remaining을 0으로 만들면, 다른 요청은 같은 도큐먼트를 다시 쓰려는 과정에서 더 이상 조건에 맞지 않게 됩니다.
그렇다면 결과는:
// 먼저 반영된 요청
{ acknowledged: true, matchedCount: 1, modifiedCount: 1 }
// 이후 조건이 맞지 않게 된 요청
{ acknowledged: true, matchedCount: 0, modifiedCount: 0 }애플리케이션에서는 두 번째 결과를 보고 “재고가 없다”고 처리합니다.
MongoDB가 컬렉션 전체를 lock 점유하여 순서를 만든다는 것이 아닌 같은 도큐먼트에 대한 충돌을 작은 범위에서 감지하고 단일 write의 조건을 다시 만족하는지 확인합니다.
MVCC(MultiVersion Concurrency Control) 스냅샷
읽는 쪽에서 쓰기의 중간 상태를 볼 수 있다면 격리 수준이 무너지는데, 여기서 등장하는 것은 MVCC입니다.
WiredTiger는 operation 시작 시점의 point-in-time snapshot을 기준으로 읽기를 수행합니다.
그래서 어떤 write가 진행 중이어도, 다른 reader측은 반쯤 바뀐 도큐먼트를 읽지 않습니다.
예를 들어 하나의 주문 도큐먼트에 대해 아래와 같은 변경이 일어난다고 해보면:
db.orders.updateOne(
{ _id: "order-1" },
{
$set: {
status: "CONFIRMED",
confirmedAt: new Date(),
paymentStatus: "PAID"
}
}
)다른 요청은 이 도큐먼트를 읽을 때:
- 변경 이전의 스냅샷 or
- 변경 이후의 스냅샷
둘 중 하나를 보게 됩니다. status는 CONFIRMED인데 paymentStatus는 예전 값인 식의 중간 상태를 보게 두지 않는다는 의미입니다.
checkpoint와 journal
메모리 안에서는 원자적이고 snapshot도 보지만, 서버가 죽으면 어떻게 될까요?
WiredTiger는 이 부분을 checkpoint와 journal 조합으로 처리합니다.
WiredTiger가 스냅샷을 기준으로 일관된 checkpoint를 만들고, 이 checkpoint는 복구 지점(recovery point) 역할을 합니다.
새 checkpoint를 쓰는 도중에도 이전 checkpoint는 유효하며, 새 checkpoint는 메타데이터 포인터가 atomically 갱신될 때 비로소 새로운 기준점이 됩니다.
이 때 checkpoint 사이에 들어온 변경분이 있다면 어떻게할까요? WiredTiger는 write-ahead log 형태의 journal을 함께 사용합니다.
흐름을 단순화하면:
- write가 발생
- 변경 내용은 journal에 기록
- 시간이 지나면 일관된 checkpoint 생김
- 장애가 나면 마지막 유효 checkpoint 이후의 변경분을 journal replay로 복구!
Standalone 방식의 한계
너무 당연하지만 Standalone은 노드가 하나이기 때문에 단일 장애 지점(Single point of failure)이 됩니다.
단일 도큐먼트에 대한 원자성, 중간 상태를 읽지 않게 하는 스냅샷 기반 읽기, journal/checkpoint를 통한 로컬 복구 정도 지원하는 것이고 복제된 여러 노드 기준의 트랜잭션 보장은 그 위의 배포 토폴로지에서 완성됩니다.
Replica Set
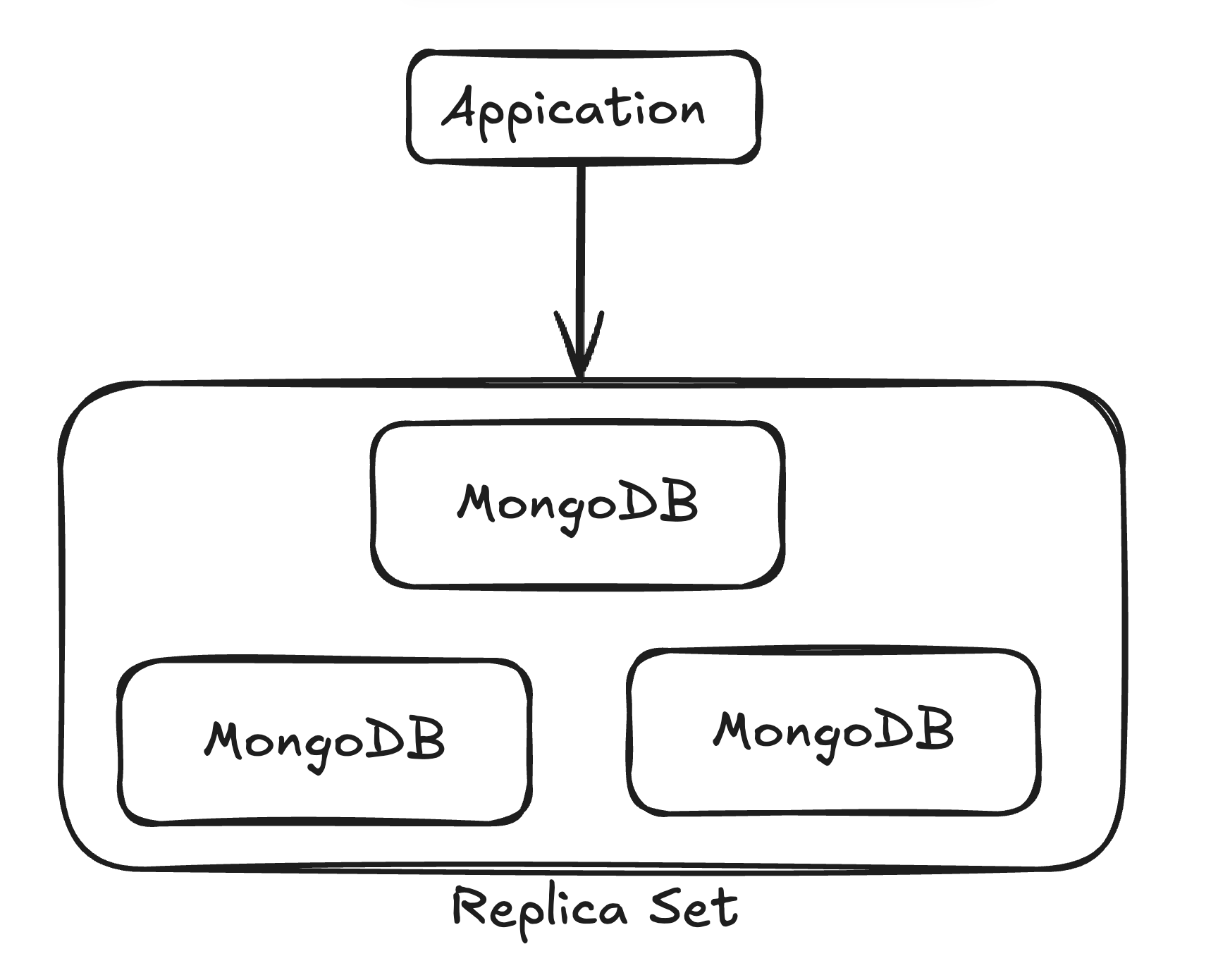
Replica Set은 여러 MongoDB 인스턴스가 같은 데이터를 복제해서 유지하는 구성입니다.
Replica Set의 흐름을 단순하게 설명하면:
client
-> primary에서 write 수행
-> primary oplog에 작업 기록
-> secondaries가 oplog를 복제하고 적용Primary는 먼저 작업을 수행하고, 그 작업을 oplog에 기록하며, Secondary는 이 oplog를 비동기적으로 복제하고 적용합니다.
이 때 oplog의 각 작업은 **idempotent(멱등)**하게 설계되어 있어, 같은 작업을 다시 적용해도 최종 상태가 어긋나지 않도록 만들어져 있습니다.
트랜잭션이 정말 의미 있으려면 commit 결과를 어떤 시점부터 안전하다고 볼지, 그리고 읽는 쪽이 어떤 시점의 데이터를 볼지 정할 수 있어야 합니다.
트랜잭션의 격리와 snapshot
MongoDB는 readConcern으로 트랜잭션 안에서 어떤 데이터를 읽을지 조절합니다.
트랜잭션 안에서 발생한 변경은 commit되기 전까지 외부에서 보이지 않습니다. 그리고 트랜잭션은 다음 read concern을 사용할 수 있습니다.
local은 현재 노드가 가진 데이터를 읽습니다majority는 과반수에 의해 확인된 데이터를 읽는 쪽에 가깝고snapshot은 트랜잭션 전체가 하나의 일관된 시점을 기준으로 읽도록 만드는 쪽에 가깝습니다
여기서 중요한 선택지가 Snapshot Isolation입니다.
MongoDB 공식 문서는 readConcern이 replica set과 sharded cluster에서 읽는 데이터의 consistency와 isolation 성격을 조절한다고 설명합니다.
그리고 multi-document transaction에서는 이 read concern을 개별 쿼리가 아니라 transaction level에서 설정합니다.
Snapshot Isolation은 어떻게 동작할까
snapshot을 사용하면 트랜잭션은 시작 시점에 읽을 기준 시점을 잡습니다. 이후 트랜잭션 안의 read는 이 기준 시점의 스냅샷을 기준으로 데이터를 반환합니다.
예를 들어 트랜잭션 A가 주문과 재고를 읽고 있다고 해보면:
T1: 트랜잭션 A 시작
T2: 트랜잭션 A가 inventory.remaining = 1 을 읽음
T3: 트랜잭션 B가 같은 inventory를 remaining = 0 으로 변경하고 commit
T4: 트랜잭션 A가 다시 inventory를 읽음readConcern: "snapshot"을 사용하면 트랜잭션 A는 T4에서도 처음 잡은 스냅샷을 기준으로 읽습니다.
즉 트랜잭션 B가 중간에 commit했더라도, 트랜잭션 A의 읽기 기준이 갑자기 바뀌지 않습니다.
중요한 점은 Snapshot Isolation이 **다른 트랜잭션의 변경을 막는다는 뜻은 아니어서 트랜잭션 B는 자기 작업을 commit할 수 있습니다.
다만 트랜잭션 A는 자기 트랜잭션이 보는 일관된 스냅샷을 유지합니다.
session.startTransaction({
readConcern: { level: "snapshot" },
writeConcern: { w: "majority" }
})snapshot read concern은 트랜잭션이 writeConcern: "majority"로 commit될 때 의미 있는 보장을 가집니다.
이때 트랜잭션 안의 작업은 majority-committed data의 스냅샷을 읽었다고 볼 수 있습니다.
정리해보면:
- 트랜잭션 시작 시 읽기 기준 시점을 잡고
- 트랜잭션 안에서는 그 스냅샷을 기준으로 읽기 때문에
- 다른 트랜잭션이 중간에 commit해도 내 트랜잭션의 읽기 결과는 흔들리지 않는다!
맺음
다음은 Replica Set에서 failover, recovery 하는 작업을 진행해보겠습니다.