A2UI - AI 에이전트가 UI를 말하는 방법
개요
2025년은 유독 에이전트 기술이 많이 등장한 해인 것 같습니다.

25년이 얼마 안남은 시점에 기세를 몰아(?) Google에서 12월 15일에 A2UI(Agent-to-User Interface)라는 기술을 공개했습니다.

먼저 소개를 살펴보면 다음과 같습니다:
A2UI는 AI 에이전트가 임의의 코드를 실행하지 않고도 웹, 모바일 및 데스크톱에서 원활하게 렌더링되는 풍부하고 상호작용적인 사용자 인터페이스를 생성할 수 있도록 한다.
에이전트에서 사용하는 일종의 규약인 것으로 보이는데 프로젝트 설명과 함께 알아봅시다.
목적과 철학
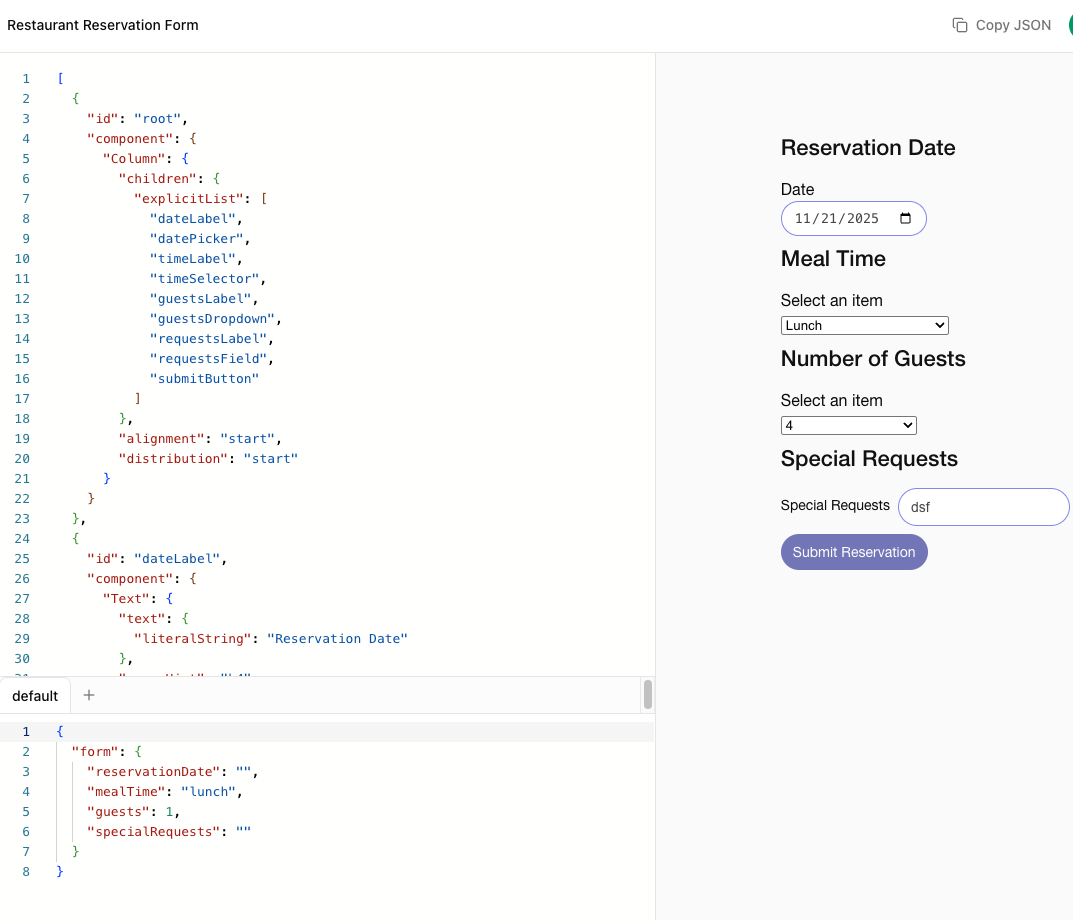
먼저 A2UI로 개선하고자 하는 점을 ‘식당 예약’을 하는 상황으로 운을 띄워봅시다:
유저: (typing) “2인용 테이블을 예약해줘.”
에이전트: “네, 몇 일부터 시작하시겠어요?”
유저: (typing) “내일.. 몇시..”
에이전트: “그 시간대에는 예약이 불가능합니다. 다른 시간대는 없을까요?”
유저: (typing) “예약 가능한 시간이 언제있지?”
에이전트: “5시, 5시 30분, 6시, 8시 30분, 9시, 9시 30분, 10시에 예약 가능합니다. 이 중 편하신 시간이 있으신가요?”
식당을 예약하는 과정에서 텍스트로만 이뤄지는 대화는 사용자와 에이전트 간 불필요한 턴을 소모하여 비효율적입니다. 필요한 정보를 한 번에 주지 않아 에이전트는 계속해서 되물어야 하기 때문이죠.
여기서 A2UI는 “에이전트가 UI라는 언어를 말하게 하자(Speak UI)“는 방향성으로 에이전트 쪽에서 식당 예약 날짜와 시간를 제출할 수 있는 버튼 양식을 직접 만들어 더 나은 사용자 경험을 제공합니다.
여기서 포인트는 화면을 어떻게 그릴지 구체적으로 명령하는 코드가 아니라 ‘선언적인 형태로 JSON으로 그 의도를 전달’ 한다는 것입니다. 즉, 에이전트가 생성하는 것이 텍스트가 아니라 UI 컴포넌트의 구조 자체를 데이터로 생성하는 것이죠.
이제 클라이언트 측에서는 선언형 JSON 데이터를 받아 웹, 모바일 등 자신의 플랫폼에 맞는 네이티브 컴포넌트로 렌더링 할 수 있게됩니다.
좀 더 구체적인 응용 사례로 살펴볼까요?
예시는 사용자가 자신의 정원이나 작업 공간의 사진을 업로드한 뒤에, 해당 공간의 조경 설계에 필요한 구체적인 요구사항을 파악하는 상황입니다.
정적 폼이 아닌 맞춤형 입력 양식을 즉석에서 생성하여 A2UI 메시지로 전송합니다.
텍스트로 일일이 설명할 필요 없이, 에이전트가 업로드한 사진을 보고 만들어준 UI를 통해 쉽고 정확하게 정보를 입력할 수 있게 된 것이죠.
철학
선언적 데이터를 다룸으로써 가장 최우선으로 얻을 수 있는 것은 ‘보안’ 입니다.
UI를 선언적으로 만듦으로써 Agent는 실행 가능한 코드를 보내지 않고, ‘스펙’만을 전달하게 되는데 이로서 임의 코드 실행을 방지할 수 있는 보안성을 가집니다.
또한 ‘UI 구조’와 ‘UI 구현’을 분리하여 프레임워크에 구애받지 않고 이식할 수 있습니다.
<Button
variant="primary"
onClick={handleSubmit}
className="bg-blue-500 hover:bg-blue-600 rounded-lg px-4 py-2"
>
submit
</Button>예시는 React로 만든 ‘제출 버튼 기능’입니다.
UI를 코드로 생성하게 되면 구조와 구현이 하나로 묶여있게 되고, React 에서만 동작하게 됩니다.
// 예시
{
"type": "a2ui",
"surface": {
"components": [
{
"id": "btn1",
"type": "Button",
"props": {
"label": "제출하기",
"variant": "primary",
"action": "submit"
}
}
]
}
}반면 에이전트가 JSON 형식으로 생성한 UI 구조는 특정 플랫폼에 얽매이지 않습니다. 각 플랫폼의 렌더러(Renderer)에서 책임을 지게 되는 것이죠.
여기서 짚고 가야할 점은 A2UI는 ‘UI를 그려내는 기술”이 아니라는 것입니다. 화면을 렌더링하는 작업은 여전히 클라이언트의 책임이며, 에이전트는 무엇을 그려야 하는지 데이터만 정의만 내릴 뿐입니다.
동작 흐름이 어떻게 되는걸까?
설명은 각설하고 한 번 써봅시다.
copilotkit으로 직접 API key를 넣고 테스트해볼 수 있긴한데, 저희의 API 한도는 소중하니까 a2ui-composer로 진행해보겠습니다. (어차피 이것도 copilotkit로 돌아갑니다)
프롬프트로 항공권 조회 컴포넌트 생성을 요청했습니다.
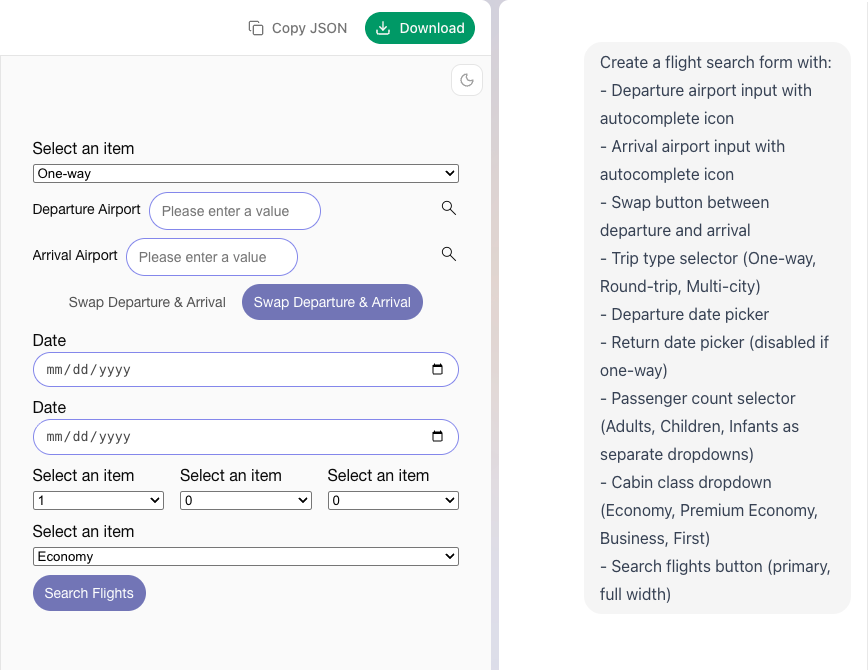
요청 프롬프트와 결과는 위와 같습니다. (JSON은 생략했습니다.)
그런데 저희는 이미 선언적 형태의 데이터로 다룬다는 것을 알고 있기 때문에 생성된 JSON과 컴포넌트 생성물의 결과는 그다지 중요하지 않습니다.
어떤 흐름으로 동작하는지가 알아봐야합니다.
1. Server Stream
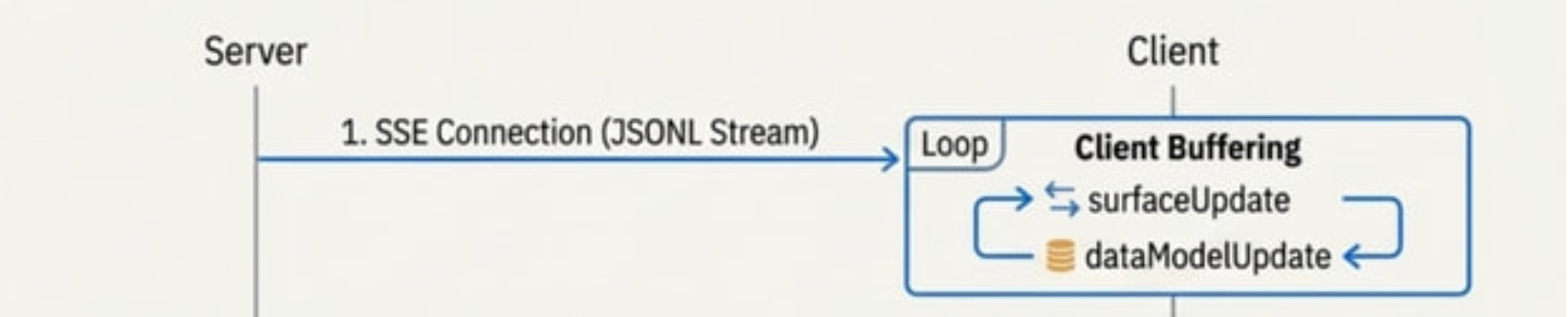
먼저 AI 에이전트가 SSE 연결을 통해 A2UI 형식의 JSONL 스트림을 전송합니다.
에이전트는 사용자 요청을 처리하면서 UI 구조와 데이터를 A2UI 규격에 맞춰 생성하는데, 이 JSON 데이터가 실시간으로 CopilotKit에게 전달됩니다.
2. Client Buffering
CopilotKit의 AG-UI 레이어가 서버에서 오는 A2UI 메시지를 수신합니다. 메시지를 파싱하면서 두 가지를 버퍼에 저장합니다.
첫 번째는 surfaceUpdate로 UI 컴포넌트 구조 정보입니다. 어떤 컴포넌트가 어떤 props를 가지고 어떻게 배치되는지 정의합니다.
두 번째로는 dataModelUpdate로 UI에 바인딩될 실제 데이터입니다. 항공편 목록, 가격, 좌석 정보 등이 여기 담깁니다.
CopilotKit은 이 단계에서 아직 화면에 그리지 않고 데이터를 모읍니다.
3. Render Signal
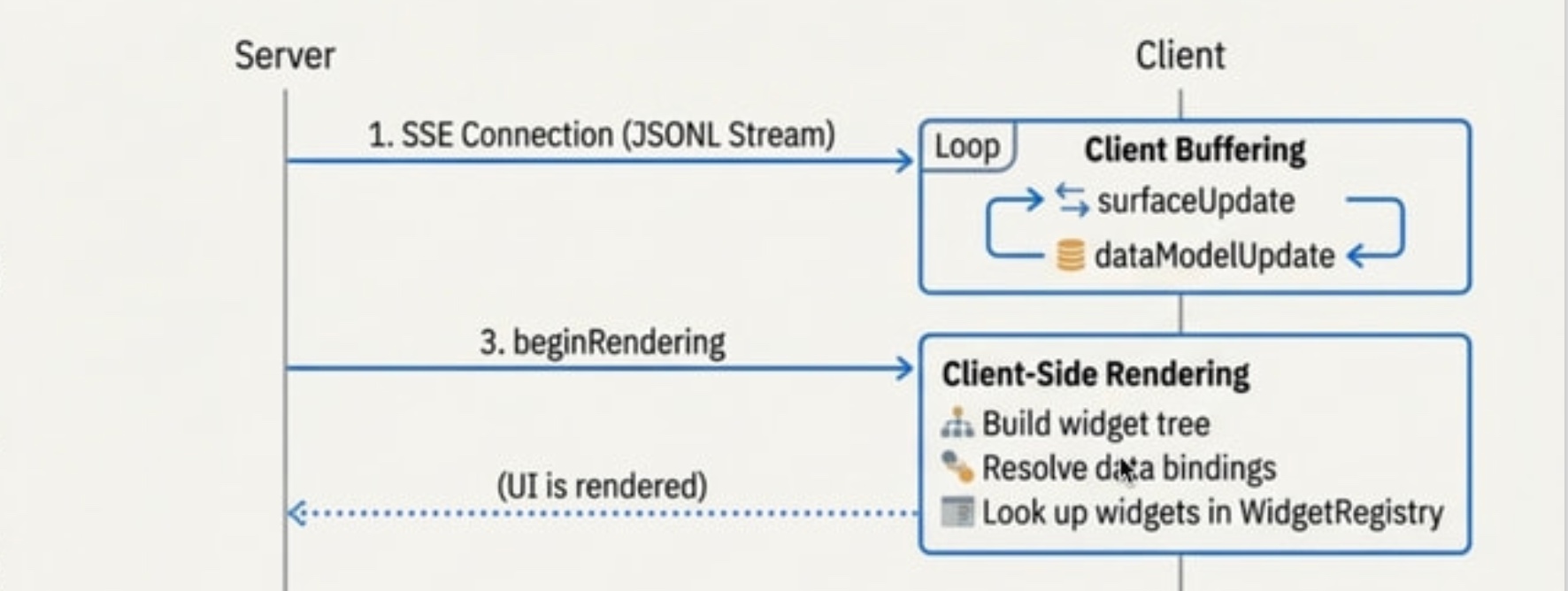
서버가 beginRendering 신호를 보냅니다.
이 신호는 불완전한 콘텐츠가 깜빡이며 나타나는 현상(flash of incomplete content)을 방지하기 위함인데, 클라이언트(CopilotKit)는 이 신호를 받기 전까지는 버퍼링만 하고, 신호를 받은 후에야 렌더링을 시작합니다.
4. Client-Side Rendering
beginRendering 신호를 받으면 CopilotKit의 A2UIRenderer가 실제 렌더링을 수행합니다. 이 과정은 세 단계로 이루어지는데:
- 위젯 트리를 구축: surfaceUpdate에 정의된 컴포넌트 구조를 바탕으로 트리를 구성
- 데이터 바인딩 해결: dataModelUpdate의 데이터를 각 컴포넌트에 연결
- WidgetRegistry에서 위젯을 조회: 컴포넌트 타입(예: “FlightCard”)을 실제 네이티브 위젯(예: React의 FlightCard 컴포넌트)으로 매핑하여 인스턴스화합니다.
이 과정이 완료되면 사용자 화면에 UI가 표시됩니다.
5. User Interaction
사용자가 CopilotKit이 렌더링한 UI와 상호작용합니다. 버튼을 클릭하거나, 폼에 값을 입력하거나, 드롭다운을 선택하는 등의 행동을 합니다.
CopilotKit은 이 인터랙션을 감지하고 userAction 페이로드를 구성합니다. 이 페이로드에는 어떤 액션이 발생했는지, 어떤 데이터가 포함되어 있는지가 담깁니다.
6. Event Handling
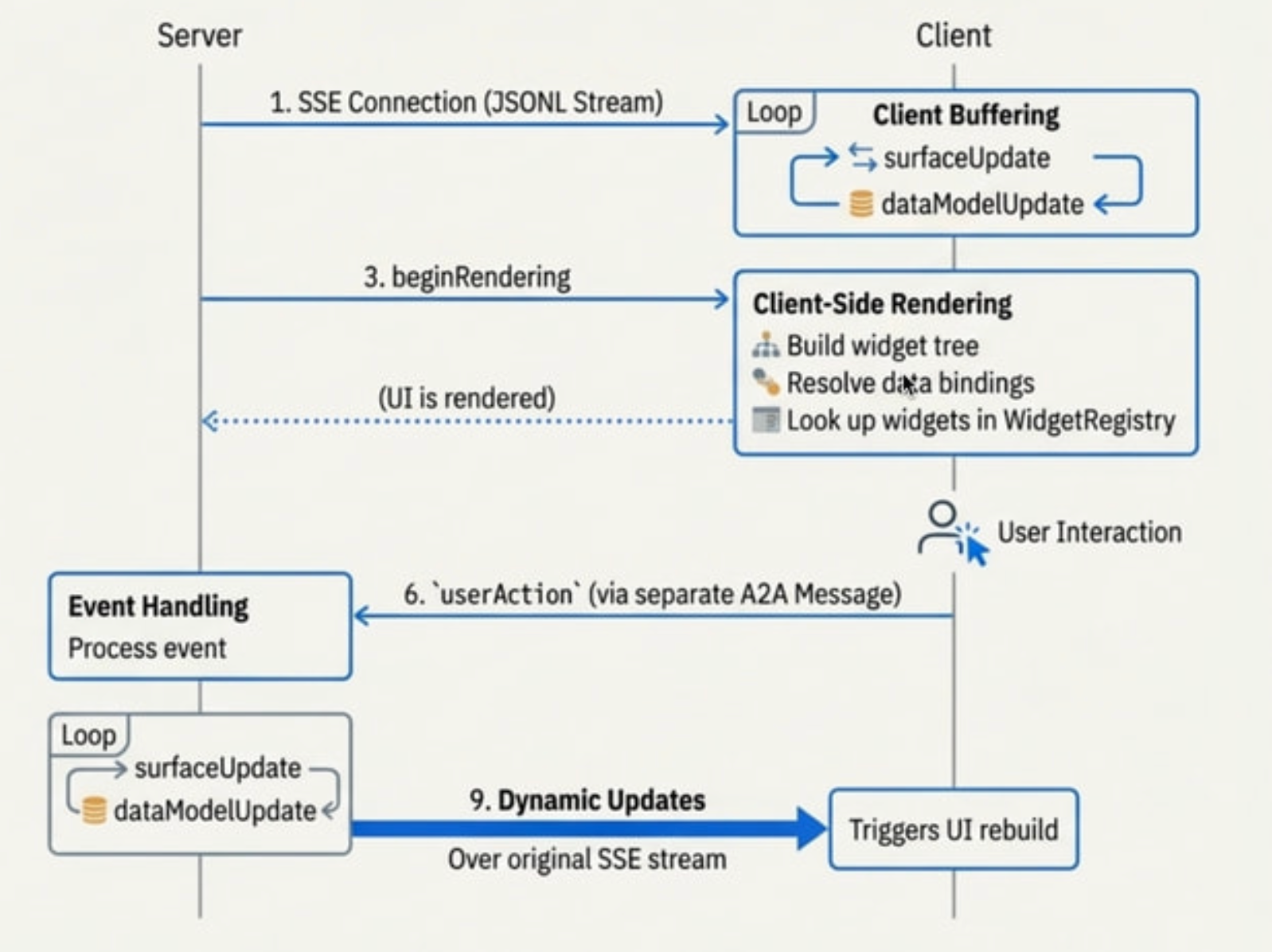
구성된 userAction이 별도의 A2A 메시지를 통해 서버로 전송됩니다.
저희는 CopilotKit의 AG-UI 레이어가 userAction을 별도의 A2A 메시지로 AI 에이전트에게 전송합니다.
7. Dynamic Updates
AI 에이전트가 액션을 처리한 후, 새로운 A2UI 메시지(surfaceUpdate 또는 dataModelUpdate)를 원래 SSE 스트림으로 전송합니다.
CopilotKit은 이 업데이트를 받아 A2UIRenderer를 통해 UI를 다시 빌드합니다. 사용자가 항공편을 선택했다면 다음 단계인 승객 정보 입력 폼이 렌더링되는 것이죠.
맺음
글을 다 작성하고 알았는데 Google에서 disco라는 앱을 만들어주는 브라우저를 공개했더군요.
A2UI 프로토콜을 적극 푸시하려고 하는 것 같습니다. 또한 Gemini 3 모델에 힘입어 에이전트와 브라우저에도 신경을 쓰려는 것 같네요.
아직 기술 도입에 드는 비용이나 안정성을 논하기에는 일주일 밖에 되지 않은 기술이지만, 프론트엔드에서 어떤 변화점을 가져올 지 궁금합니다.
Google에서 만들어서 그런지 Angular를 먼저 지원하는 도그 푸딩을 선보였지만, 조만간 React나 다른 프레임워크에서도 지원하는 모습을 볼 수 있을 것 같습니다.
조금 갖고 놀면서 사용해본 프론트엔드 개발자들의 후기와 의견을 기다려봐야겠습니다.