MongoDB와 RDB를 비교해보자
개요
MongoDB를 프로젝트에 사용하면서 NoSQL이라는 사실만 알고 있었는데, 그나마(?) 저에게 익숙한 개념인 RDB(관계형 데이터베이스)와 비교하여 정리해봤습니다.
이 글에서는 MongoDB를 “테이블 대신 컬렉션을 쓰는 DB” 정도로만 보지 않고, RDB와 사고방식이 얼마나 다른지 위주로 비교하겠습니다.
등장 배경
MongoDB를 왜 쓰는지에 대해 알아보기 전에 등장 배경에 대해 알아보겠습니다.
MongoDB의 공동 창립자인 드와이트 메리먼, 엘리엇 호로위츠, 케빈 라이언은 온라인 광고 회사 DoubleClick에서 대규모 트래픽을 다뤘던 경험이 있었습니다. MongoDB 공식 소개에서도 이들이 초당 40만 건 이상의 광고를 처리하는 규모에서 관계형 데이터베이스의 한계를 경험했습니다.
문제는 당시 RDB가 그 수준의 트래픽을 수평으로 확장하기 쉽게 설계되지 않았고, 그들은 직접 해결책을 만들기로 하고 2007년에 10gen을 창업했습니다.
그런데 그들의 처음 목표는 데이터베이스가 아닌 클라우드 기반 PaaS 플랫폼이었습니다.
Google App Engine과 유사한 플랫폼을 만들려 했고, 데이터베이스는 그 안의 부품 중 하나였습니다.
그런데 당시 존재하던 데이터베이스가 원하는 클라우드 아키텍처 요건을 충족하지 못했습니다. 결국 팀은 데이터베이스까지 직접 만들기 시작했죠.
흥미로운 점은 개발자들이 플랫폼보다 그 안의 데이터베이스에 더 큰 관심을 보였다는 것입니다.
결국 10gen은 PaaS 전체를 내려놓고, 데이터베이스 하나에 집중하기로 결정합니다. 이 후 2009년, MongoDB가 오픈소스로 공개되었습니다.
당시에는 인터넷 서비스가 커지고, 장치와 사용자 로그가 폭발적으로 늘어나면서 전통적인 RDB로 다루기 까다로운 데이터가 많아졌습니다. 완전히 정해진 테이블 구조에 넣기 어려운 데이터, 빠르게 바뀌는 요구사항, 큰 트래픽을 처리하기 위한 수평 확장이 중요한 문제가 됐습니다.
MongoDB는 이 문제를 “관계형 모델을 더 잘 흉내내는 방식”이 아니라, 도큐먼트 모델로 풀었습니다.
RDB와 MongoDB 비교하기
테이블(table) vs 도큐먼트(document)
CREATE TABLE reservations (
id BIGINT PRIMARY KEY,
property_id BIGINT NOT NULL,
guest_name VARCHAR(255) NOT NULL,
check_in DATE NOT NULL,
check_out DATE NOT NULL
);먼저 RDB의 기초적인 데이터 집합인 테이블은 행과 열로 구성되고, 테이블 간 관계는 보통 Primary Key와 Foreign Key로 표현합니다.
{
"_id": "reservation-1",
"propertyId": "property-1",
"guestName": "홍길동",
"dateRange": {
"checkIn": "2026-05-01",
"checkOut": "2026-05-03"
}
}MongoDB는 데이터를 컬렉션 안의 도큐먼트로 저장하며, BSON(Binary JSON)이라는 데이터 형식으로 저장합니다.
일반 JSON과 큰 차이가 없어 보이는데 무슨 특성을 가지고 있을까요?
{
"_id": "507f1f77bcf86cd799439011",
"createdAt": "2026-04-12T12:00:00Z",
"price": 1000
}BSON은 JSON 형태에 날짜, ObjectId 같은 타입을 더한 이진 표현입니다.
일반 JSON 파일에서는 _id는 문자열이고, createdAt도 문자열입니다.
반면 BSON은 필드마다 타입 정보를 함께 저장합니다.
[문서 전체 길이]
[필드 타입][필드명][값]
[필드 타입][필드명][값]
...
[문서 끝]그래서 MongoDB는 createdAt을 문자열이 아니라 BSON의 Date 타입으로 저장할 수 있고, _id도 단순 문자열이 아니라 ObjectId 타입으로 저장할 수 있습니다.
바이너리 데이터도 base64 문자열로 우회하지 않고 Binary 타입으로 저장할 수 있습니다.
Binary로 다뤄서 얻는 이점은 크게 세 가지인데:
-
Date,ObjectId,Binary,Decimal128,int32,int64같은 타입을 MongoDB 내부 타입으로 다룰 수 있으며 -
텍스트를 매번 파싱하지 않아도 됩니다. BSON은 타입과 길이 정보를 갖고 있기 때문에 MongoDB가 값을 읽을 때 어디까지가 해당 값인지 더 빠르게 알 수 있고
-
숫자와 바이너리 데이터를 문자열로 바꾸지 않고, 숫자는 숫자 타입으로, 바이너리 데이터는 바이트 배열로 저장할 수 있습니다.
BSON은 필드 타입과 길이 정보 같은 메타데이터를 추가로 저장하는 특징이 있는데, 예를 들어 JSON의 1은 한 글자지만, BSON의 int32 값은 값 자체만 4바이트를 사용하게 됩니다.
이로써 MongoDB가 문서를 타입 정보와 함께 빠르게 다룰 수 있습니다.
스키마(Schema)를 다루는 법
처음 공식 문서를 보고 의아했던 것은 schema라는 표현을 계속 사용하는데, RDB에서 말하는 스키마와 MongoDB 문서에서 말하는 스키마는 느낌이 조금 달랐던 것입니다.
CREATE TABLE reservations (
id BIGINT PRIMARY KEY,
guest_name VARCHAR(255) NOT NULL,
status VARCHAR(20) NOT NULL,
check_in DATE NOT NULL,
check_out DATE NOT NULL
);RDBMS 시스템에서는 스키마를 강제합니다. guest_name이 없거나, check_in에 날짜로 해석할 수 없는 값이 들어오면 DB가 거부하고, 컬럼을 추가하거나 타입을 바꾸려면 ALTER TABLE 같은 DDL을 실행해야 합니다.
즉 RDB에서의 스키마는 대체로 테이블 구조 + 컬럼 타입 + 제약 조건입니다.
하지만 여기서 비교하는 것은 namespace로서의 스키마가 아니라, 테이블이 어떤 컬럼과 제약을 갖는지에 대한 테이블 스키마입니다.
반면 MongoDB에서 말하는 schema는 기본적으로 컬렉션 안의 도큐먼트들이 대체로 어떤 구조를 갖는가에 가깝습니다.
MongoDB는 기본적으로 같은 컬렉션 안에서도 도큐먼트마다 필드가 다를 수 있습니다.
db.reservations.insertMany([
{
_id: "reservation-1",
guestName: "홍길동",
status: "CONFIRMED"
},
{
_id: "reservation-2",
guest: {
name: "김철수"
},
memo: "늦은 체크인 요청"
}
])둘 다 같은 reservations 컬렉션에 들어갈 수 있는데:
첫 번째 도큐먼트는 guestName을 문자열로 갖고 있고, 두 번째 도큐먼트는 guest라는 중첩 객체를 갖고 있습니다.
이게 MongoDB 공식 문서에서 말하는 flexible schema입니다. 문서마다 반드시 같은 필드 집합을 가질 필요가 없고, 같은 필드라도 도큐먼트마다 타입이 달라질 수 있습니다.
하지만 이 말이 “스키마가 없다”는 뜻은 아니고, 애플리케이션이 기대하는 구조는 여전히 존재합니다.
예를 들어 예약을 처리하는 코드가 guestName과 status를 기대한다면, 이 구조가 사실상의 application 스키마가 됩니다.
차이는 그 스키마가 처음부터 DB에 의해 강제되는지, 아니면 애플리케이션과 규칙으로 먼저 존재하는지입니다.
필요하다면 schema validation을 걸 수 있습니다.
db.createCollection("reservations", {
validator: {
$jsonSchema: {
bsonType: "object",
required: ["guestName", "status"],
properties: {
guestName: { bsonType: "string" },
status: {
enum: ["PENDING", "CONFIRMED", "CANCELLED"]
}
}
}
}
})이렇게 하면 guestName과 status 같은 필드를 검증할 수 있습니다. MongoDB의 validation rule은 필요한 부분에만 적용할 수 있고, 모든 필드를 빠짐없이 정의해야 하는 것도 아닙니다.
그래서 MongoDB를 schema-less가 아니라 schema를 미리 강하게 고정하지 않는 flexible schema 모델에 가깝다고 볼 수 있습니다.
레퍼런스(reference)와 임베드(embed)
MongoDB에서 컬렉션은 도큐먼트를 묶는 단위입니다. RDB의 테이블과 비슷한 위치에 있지만, table처럼 모든 row가 같은 column 구조를 가져야 하는 것은 아닙니다.
관계가 있는 데이터를 저장할 때 MongoDB 공식 문서는 크게 두 가지 모델을 이야기합니다.
레퍼런스(reference): 다른 도큐먼트의 id를 저장하고 필요할 때 따라가는 방식임베드(embed): 관련 데이터를 현재 도큐먼트 안에 중첩 객체나 배열로 함께 넣는 방식
예를 들어 예약과 숙소가 있다고 해보겠습니다.
{
"_id": "reservation-1",
"guestName": "홍길동",
"propertyId": "property-1"
}이건 레퍼런스 방식입니다. 예약 도큐먼트는 숙소 이름과 주소를 직접 갖고 있지 않고, propertyId만 갖고 있습니다.
{
"_id": "property-1",
"name": "강릉 오션뷰 스테이",
"address": "강원도 강릉시 ..."
}숙소 정보의 원본은 properties 컬렉션의 도큐먼트에 있습니다.
반대로 같은 데이터를 임베드 방식으로 설계한다면:
{
"_id": "reservation-1",
"guestName": "홍길동",
"property": {
"_id": "property-1",
"name": "강릉 오션뷰 스테이",
"address": "강원도 강릉시 ..."
}
}관련 데이터를 별도 도큐먼트로 분리하지 않고, 현재 도큐먼트 안에 함께 저장하는 방식입니다.
위 예시에서는 예약 도큐먼트 안에 숙소 정보 일부를 중첩 객체로 넣었습니다.
reservation document
└─ property
├─ _id
├─ name
└─ address이 경우에는 예약 하나를 조회할 때 숙소 이름과 주소까지 같이 읽을 수 있습니다.
db.reservations.findOne({ _id: "reservation-1" })여기서 “조회 한 번”이라는 말은 reservations 컬렉션에서 예약 도큐먼트 하나를 읽었는데, 그 도큐먼트 안에 화면에 필요한 property.name, property.address가 이미 들어 있다는 의미입니다.
대신 같은 숙소 정보가 여러 예약 도큐먼트에 반복 저장될 수 있습니다.
{
"_id": "reservation-2",
"guestName": "파랑 피크민",
"property": {
"_id": "property-1",
"name": "강릉 오션뷰 스테이",
"address": "강원도 강릉시 ..."
}
}이 경우 reservation-1과 reservation-2는 서로 다른 예약 도큐먼트입니다. 따라서 도큐먼트 자체가 중복된 것은 아닙니다.
다만 두 도큐먼트 안에 같은 property-1의 이름과 주소가 복사되어 있습니다. MongoDB에서 말하는 비정규화나 중복 허용은 보통 이런 상황을 말합니다.
RDB와 MongoDB에서의 관계(Relation)
RDB에서는 관계를 보통 Foreign Key와 join으로 다룹니다.
reservations
id
property_id
guest_name
properties
id
name
address여기서 reservations.property_id는 properties.id를 가리키는 참조 값이며, join은 그 참조 값을 이용해 조회 시점에 두 테이블의 데이터를 합치는 연산입니다.
SELECT r.id, r.guest_name, p.name, p.address
FROM reservations r
JOIN properties p ON r.property_id = p.id
WHERE r.id = 1;MongoDB에서도 레퍼런스를 저장하고 나중에 따라갈 수 있습니다.
{
"_id": "reservation-1",
"guestName": "홍길동",
"propertyId": "property-1"
}이 방식에서는 숙소 정보가 필요할 때 애플리케이션에서 properties 컬렉션을 한 번 더 조회할 수 있습니다.
db.properties.findOne({ _id: "property-1" })또는 aggregation의 $lookup을 사용해 컬렉션 간 데이터를 합칠 수 있습니다.
db.reservations.aggregate([
{
$lookup: {
from: "properties",
localField: "propertyId",
foreignField: "_id",
as: "property"
}
}
])다만 MongoDB에서는 RDB처럼 join을 설계의 기본 전제로 두기보다, 애플리케이션이 데이터를 읽는 모양에 맞춰 reference와 embed 중 하나를 선택합니다.
즉 레퍼런스는 데이터를 정규화하는 쪽에 가깝고, 임베드는 데이터를 비정규화하는 쪽에 가깝습니다.
수평 확장과 샤딩(sharding)
전통적인 RDB에서는 샤딩을 애플리케이션이나 운영 설계에서 직접 감당해야 하는 경우가 많습니다.
예를 들어 예약 데이터를 property_id 기준으로 나눈다고 해보겠습니다.
reservations_property_1_1000 -> shard A
reservations_property_1001_2000 -> shard B
reservations_property_2001_3000 -> shard C이렇게 나누면 애플리케이션은 어떤 예약이 어느 shard에 있는지 알아야 합니다.
property_id = 1200이면 shard B로 보내고, property_id = 300이면 shard A로 보내야 합니다.
즉 RDB에서 샤딩은 결국
- shard 간 join이 어려워지고
- 특정 shard에 트래픽이 몰릴 수 있으며
- 데이터가 커지면 다시 쪼개고 옮기는 작업이 필요하고
- transaction과 consistency 경계가 복잡해져서
애플리케이션과 운영 복잡도가 함께 커지는 방식에 가깝습니다.
MongoDB는 이 문제를 데이터베이스 기능으로 더 직접적으로 다루며 sharded cluster를 다음과 같이 구성합니다:
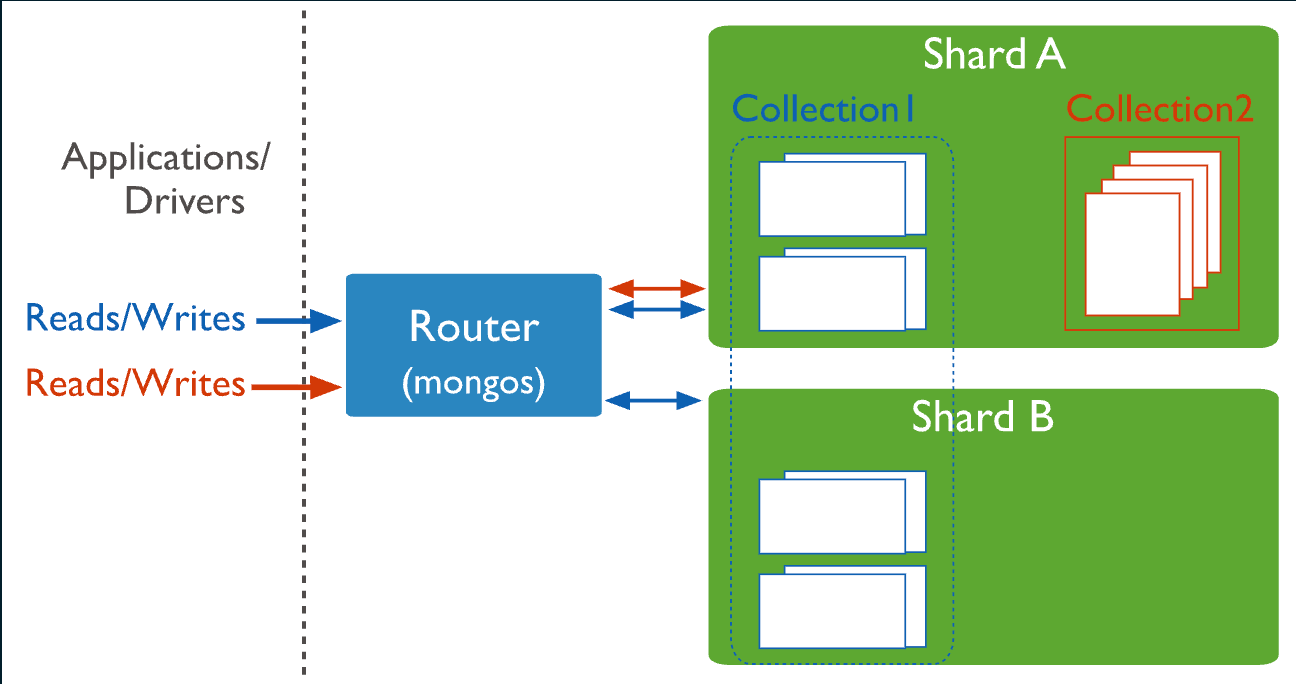
애플리케이션은 보통 mongos라는 라우터에 요청을 보냅니다. mongos는 shard key를 보고 어떤 shard로 요청을 보낼지 결정합니다.
예를 들어 reservations 컬렉션을 propertyId 기준으로 shard한다고 하면, MongoDB는 shard key 값을 기준으로 데이터를 여러 shard에 나눠 저장합니다.
sh.shardCollection("pms.reservations", { propertyId: 1 })이때 중요한 설계 포인트는 shard key입니다.
shard key를 잘 고르면 특정 숙소의 예약을 찾는 쿼리를 필요한 shard로 보낼 수 있습니다.
db.reservations.find({ propertyId: "property-1" })반대로 shard key를 잘못 고르면 특정 shard에만 데이터나 요청이 몰릴 수 있습니다.
MongoDB의 설계 철학은 “정규화된 데이터를 조인해서 조립한다”보다, 애플리케이션의 접근 패턴에 맞춰 document와 shard key를 설계한다에 가깝습니다.
어떤 필드로 데이터를 나눌지, 어떤 쿼리가 자주 들어오는지, 한 도큐먼트 안에 어떤 데이터를 함께 둘지 같이 설계해야 합니다.
정리
사실 이것 외에도 굉장히 내용이 방대해서 두 번째 파트로 나누려고 합니다.
이후에는 mongoDB에서 트랜잭션을 어떻게 다루는지, replica set과 같은 특징을 이어서 다뤄보겠습니다.