MongoDB 부하 테스트 시험기
개요
이번 글은 부하 테스트를 진행하면서 겪은 문제를 정리한 글입니다.
프리티어로 테스트한다고 명시했지만 2025년 7월 15일부터 AWS 프리티어가 크레딧 단위로 차감되는 시스템으로 바뀌었습니다.
받을 수 있는 모든 크레딧을 긁어모으면 200달러를 제공하는데 이를 최대한 뽑아보겠습니다.
인프라, 테스트 도구 선정

부하 테스트 도구같은 경우 Jmeter, k6, ngrinder, locust가 후보였는데 K6를 선택했습니다.
Jmeter나 ngrinder는 JVM 위에서 동작하여 다른 후보군에 비해 상대적으로 무거웠지만 K6는 간단하고 직관적인 방식으로 스크립트 작성을 지원하기 때문에 선택했습니다. (무엇보다 많이 사용됩니다.)
처음 구상했던 인프라 아키텍처는 다음과 같습니다:
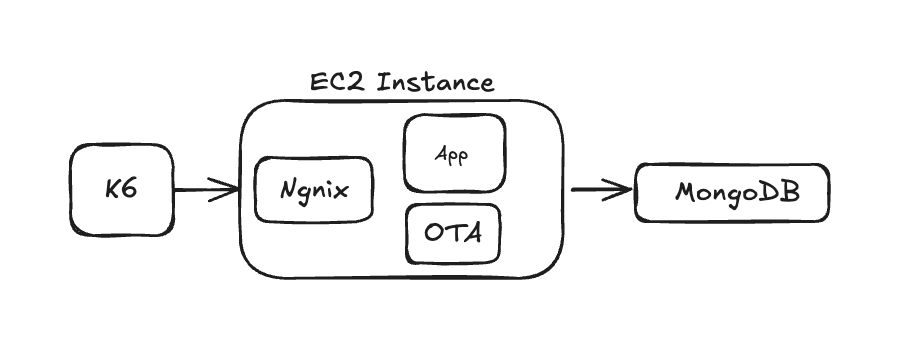
실제 프로덕션 상황을 고려한 배포 구조는 OTA 서버와 애플리케이션 서버를 분리해야 하며, 애플리케이션 서버도 2대씩 두겠지만 주 목적은 DB 병목 지점을 확인하는 것이 목적이기 때문에 단일 인스턴스에서 Docker 컨테이너를 띄우기로 했습니다.
다만 여기서 한 가지 걸리는 점이 있었는데, 부하 테스트가 실행되면 요청은 k6 -> App 서버 -> MongoDB 순서로 흘러가며 첫 진입점은 App 서버입니다.
App 서버의 하드웨어 성능이 너무 낮으면 MongoDB까지 부하가 도달하기 전에 App 서버가 먼저 병목이 될 것이라고 생각했습니다.
그래서 App 서버는 t2.small(1vCPU, 2GiB)를 할당하고 MongoDB 서버 3대는 t2.micro(1vCPU, 1GiB)를 할당하기로 했습니다.
서버를 왜 3대 뒀느냐? 이건 MongoDB failover 시나리오를 구현하기 위함입니다.
Failover는 장애 조치 기능으로 시스템 장애 발생 시 하나 이상의 예비 백업 시스템(노드) 로 자동 전환되는 것을 의미하는데요:
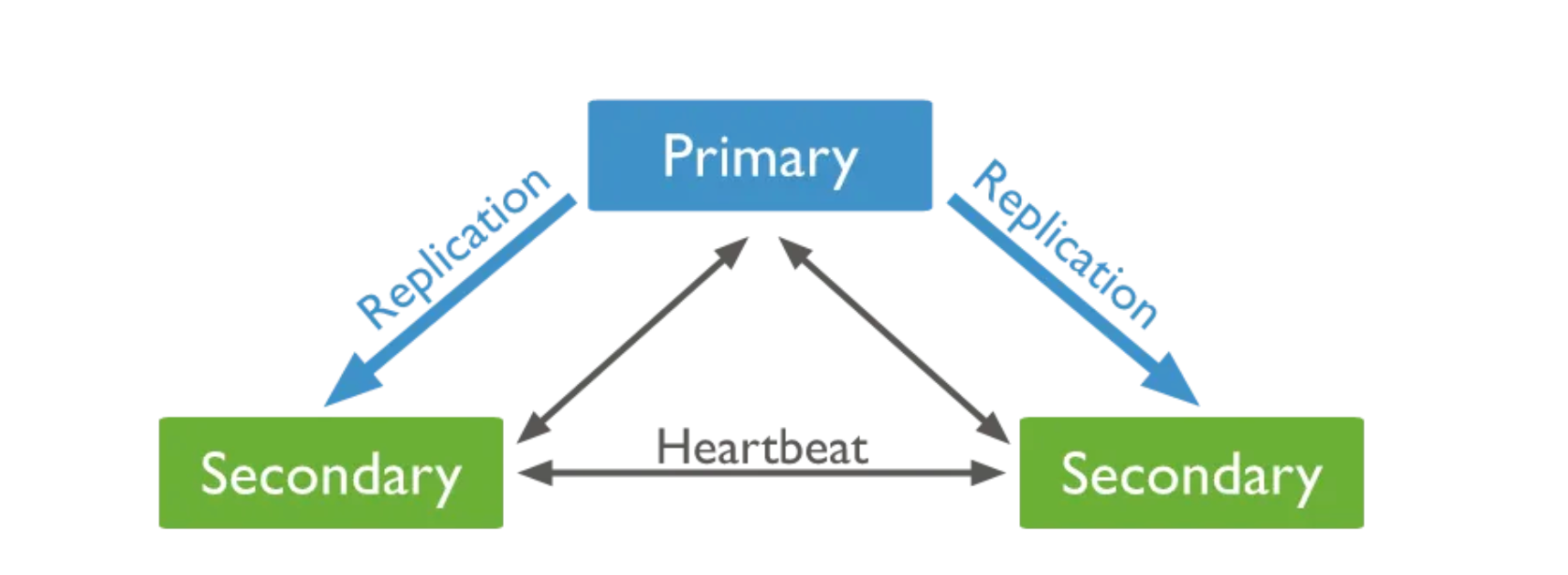
MongoDB에서 트랜잭션 및 Failover 작업을 지원하려면 Replica-set이 구성되어야 합니다.
Primary db에서 읽기 작업을 주로 처리하다가 DB가 주고받는 heartbeat가 끊기면 election을 통해서 secondary db를 승격시키고 primary를 복구하는 작업을 진행합니다.
최종적으로 결정된 아키텍처 구성은 다음과 같습니다:
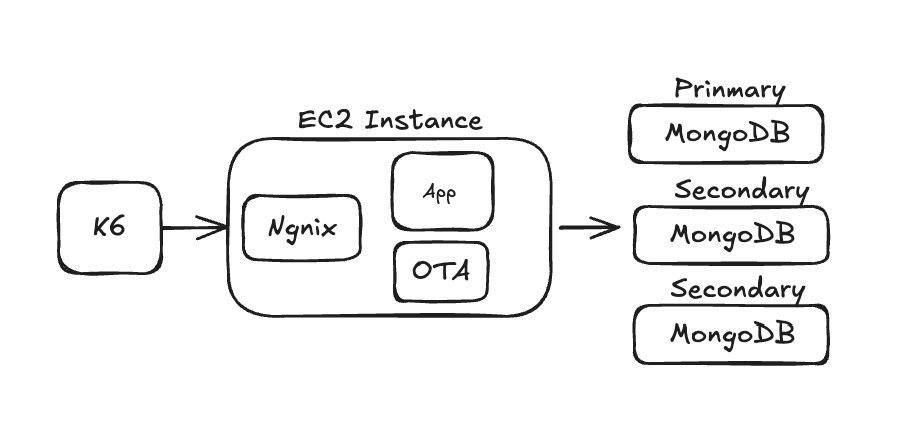

그런데 시작도 전에 Out of memeory가 발생해서 mongodb 인스턴스 3대도 t2.small(1vCPU, 2GiB)로 scale-up 해줬습니다.
실험 로그
어떤 기능을 부하 테스트 해야할까
도구와 인프라 구성은 완료됐는데 어떤 것을 테스트해야 할까요?
일단 클라이언트와 서버의 목적을 구분한다면:
클라이언트의 경우 애플리케이션의 화면이 빠르게 렌더링 되는지 혹은 사용자가 UI 컴포넌트와 상호 작용하는 시간의 속도가 관건이 될 수 있을 것이고, 서버에서는 클라이언트가 전달하는 요소들이 서버에서 어떻게 처리되고 브라우저에 의해 어떻게 다운로드되는지 같은 지표에 초점을 맞출 수 있을 것입니다.
이번 부하 테스트의 목적은 서버의 성능을 측정하기 위함이므로 클라이언트는 생략하고, 처음 생각했던 서버의 부하 테스트는 API가 ‘얼마나 자주 조회’되는지 그리고 서버의 자원이 ‘비즈니스적으로 중요한 기능(중요하지 않은 기능이 있나 싶냐마는)이 문제없이 작동해야 한다’였습니다.
그런데 현재 프로젝트에서 핵심 비즈니스 기능이라는 것을 하나의 기능이라고 퉁쳐서 설명하긴 어렵습니다. 여러 사용자가 숙소를 조회하고 결제까지 마치는 프로세스를 포함하고있기 때문입니다.
그래서 실제 사용자의 행동을 예상하여 숙소 조회 및 결제를 포함하는 end-to-end 시나리오를 테스트하기로 결정했습니다.
어떤 지표를 측정해야할까
실제 운영 중인 서비스라면 DAU나 피크 시간대 RPS, 결제 전환율같은 운영 지표를 고려하여 테스트할텐데 저희에겐 현재 어떤 기준을 만족해야 한다는 기준이 없습니다.
때문에 현재 구성된 App 서버와 DB 서버의 하드웨어 스펙으로 얼마나 많은 트래픽을 수용할 수 있는지 알아보도록 할 것입니다.
이를 위해 CUJ(Critical User Journey)라는 기준을 설정했는데, 이는 사용자들이 애플리케이션을 이용하면서 생길 수 있는 시나리오(숙소 목록 조회, 예약 생성..) 흐름을 말합니다.
여러 시나리오의 API를 호출하면서 생기는 흐름, 즉 CUJ에서 지연율(Latency)이나 실패한 요청의 비율(Error rate), 처리량(Throughput), 서버 자원의 포화 유무를 측정해볼 것입니다.
이제 테스트를 시작해보겠습니다.
Smoke test
Smoke test는 기계식 연기 검사에서 파이프나 기계에 연기를 주입하여 누출이나 결함을 확인하는 방법에서 유래되었는데, 시스템이 최소한의 부하에서 정상적으로 작동하는지 확인하고 기본 성능 값을 수집하는 작업입니다.
보통은 적은 수의 VU(Virtual User, 가상 사용자)로 짧은 시간동안 테스트를 수행합니다.
실행한 부하 테스트의 결과를 보면:
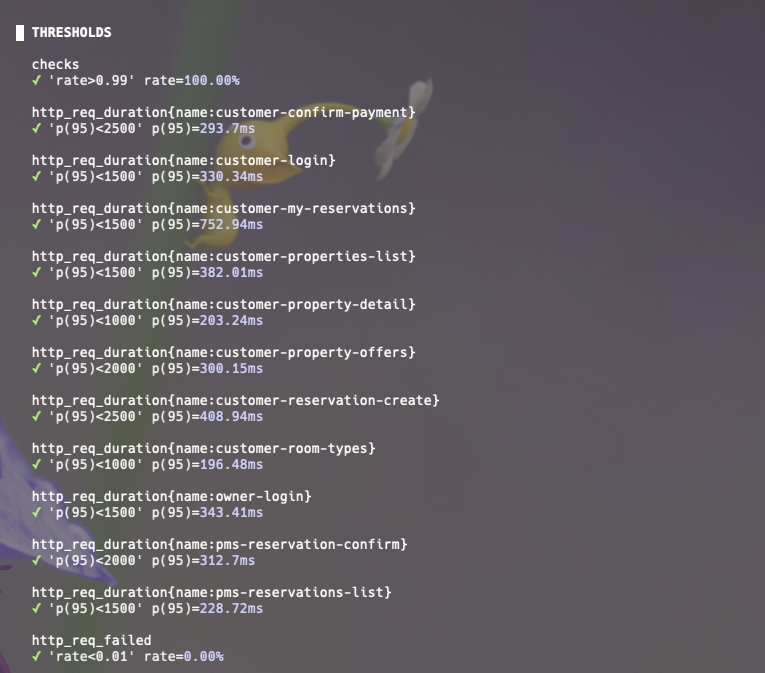
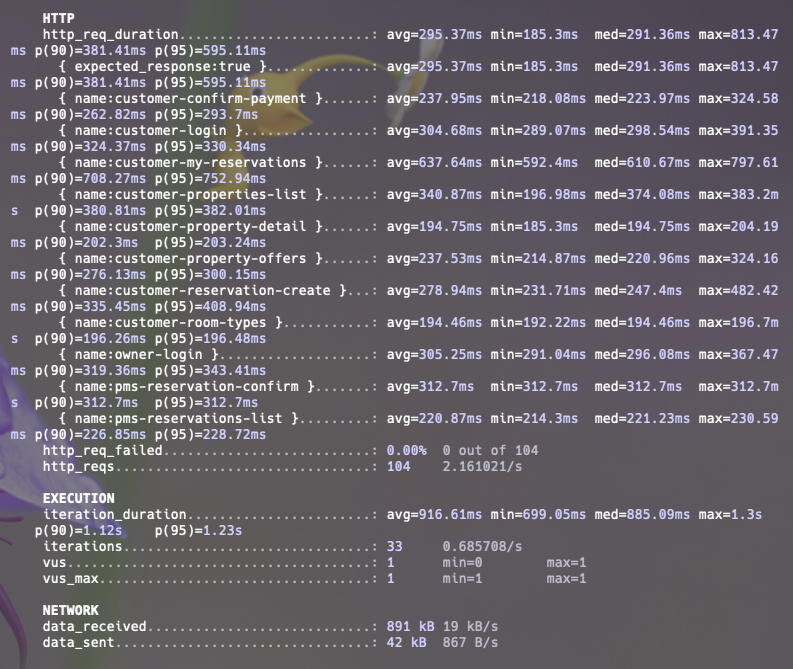
지연율이 느리다고 할 수 있는 기준을 정하지 않았지만 my-reservation 즉 내 예약을 불러오는 기능이 상대적으로 높고(797ms), 모든 요청이 성공했습니다.
Smoke test에서 최소 부하에서는 서버가 정상적으로 작동함을 확인할 수 있었습니다.
Baseline test
Baseline test는 정상적인 부하(일반적인 평시 트래픽)를 처리할 때의 성능 수치를 측정하는 테스트입니다.
첫 baseline 테스트 결과를 보면:
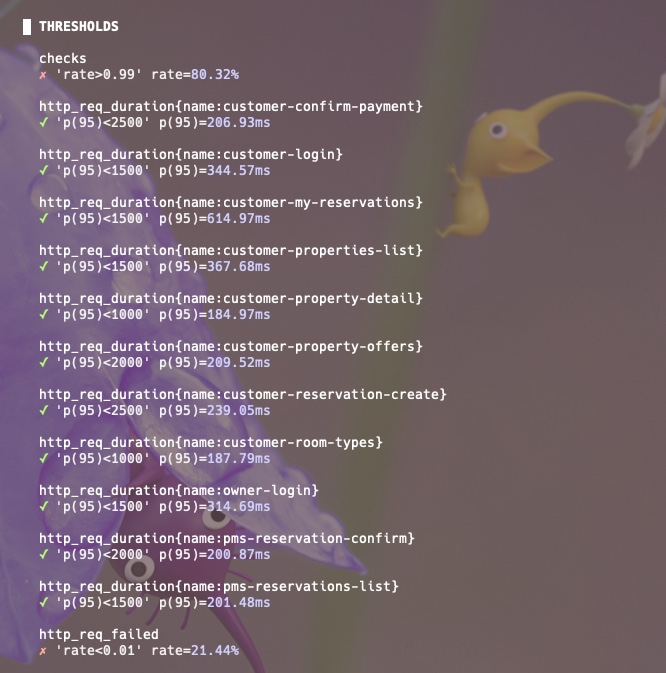
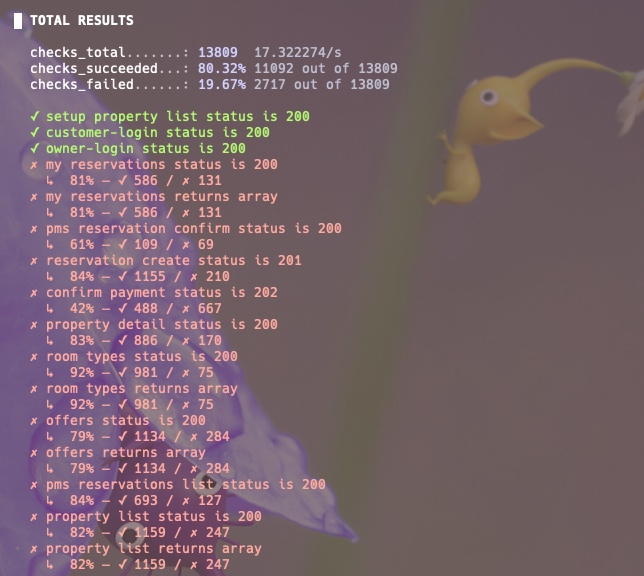
smoke test와는 다르게 실패율이 보이는데, 메트릭을 확인했을 때 하드웨어 자원 문제는 아니었습니다.
Loki로 로그를 확인해보겠습니다.
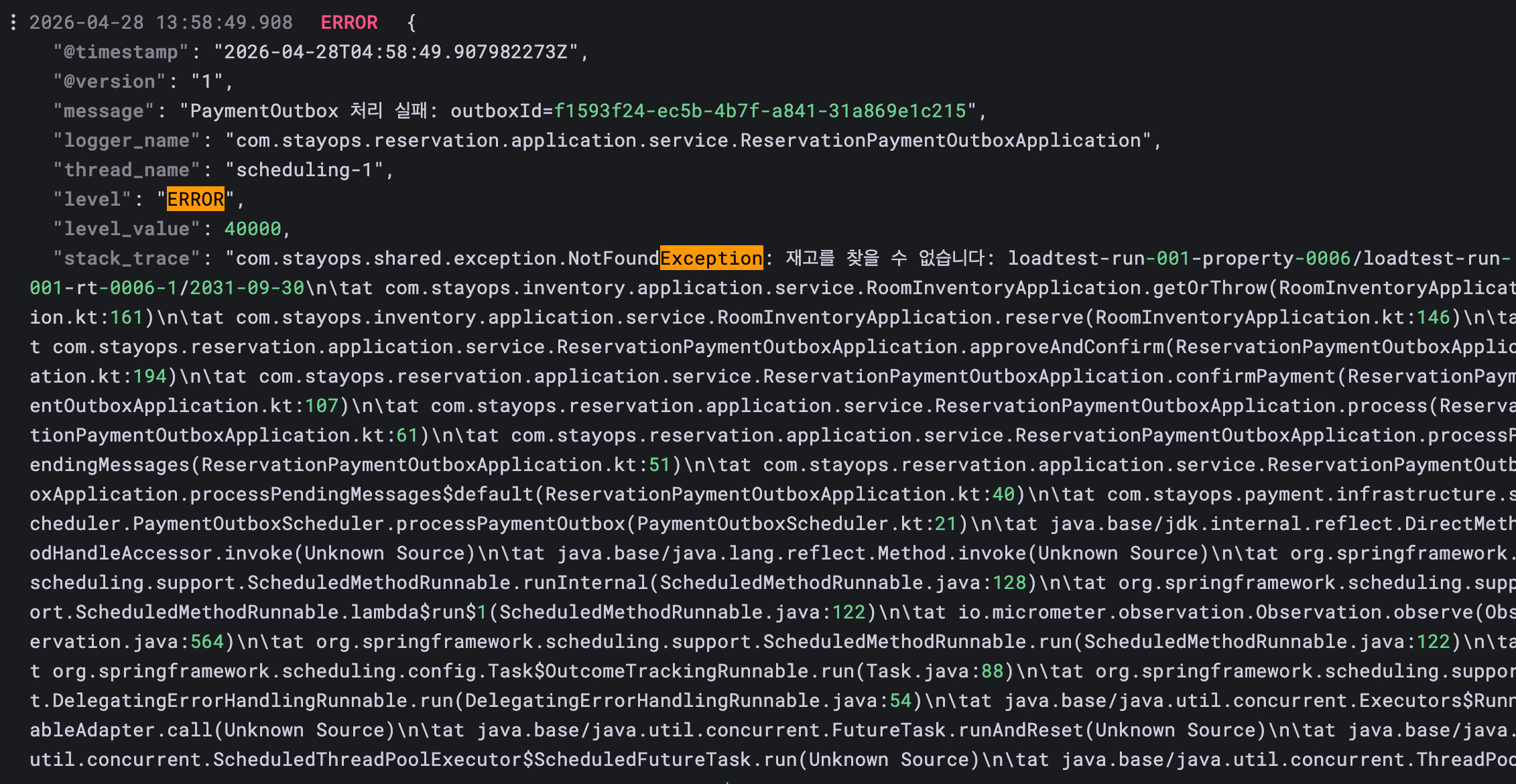
일단 스케줄러에서 PaymentOutbox 처리 실패를 나타냈습니다.
결제 기능 흐름을 보면 다음과 같은데요:
-> 예약 생성 후에 결제 확인 API를 호출하고
-> 결제 승인 요청 자체를 즉시 끝까지 처리하지 않고 PaymentOutboxMessage로 저장
-> PaymentOutboxScheduler가 일정 주기마다 처리 가능한outbox 메시지를 조회
-> 각 메시지에 대해 PG 승인, 결제 상태 저장, 예약 확정,재고 차감, 실패 시 재시도/취소 요청을 수행baseline 테스트 중 생성된 예약이나 이전 테스트에서 남은 outbox가 결제 후처리 스케줄러에 의해 처리되고 있었는데, 스케줄러가 결제 승인 후 예약 날짜의 재고를 차감하려 했지만 2031-09-30 재고 문서가 없었고 2031-09-30은 부하테스트 seed 범위와 맞지 않았습니다.
즉, 테스트 데이터 정합성에서 생긴 문제라고 추측해봤습니다.
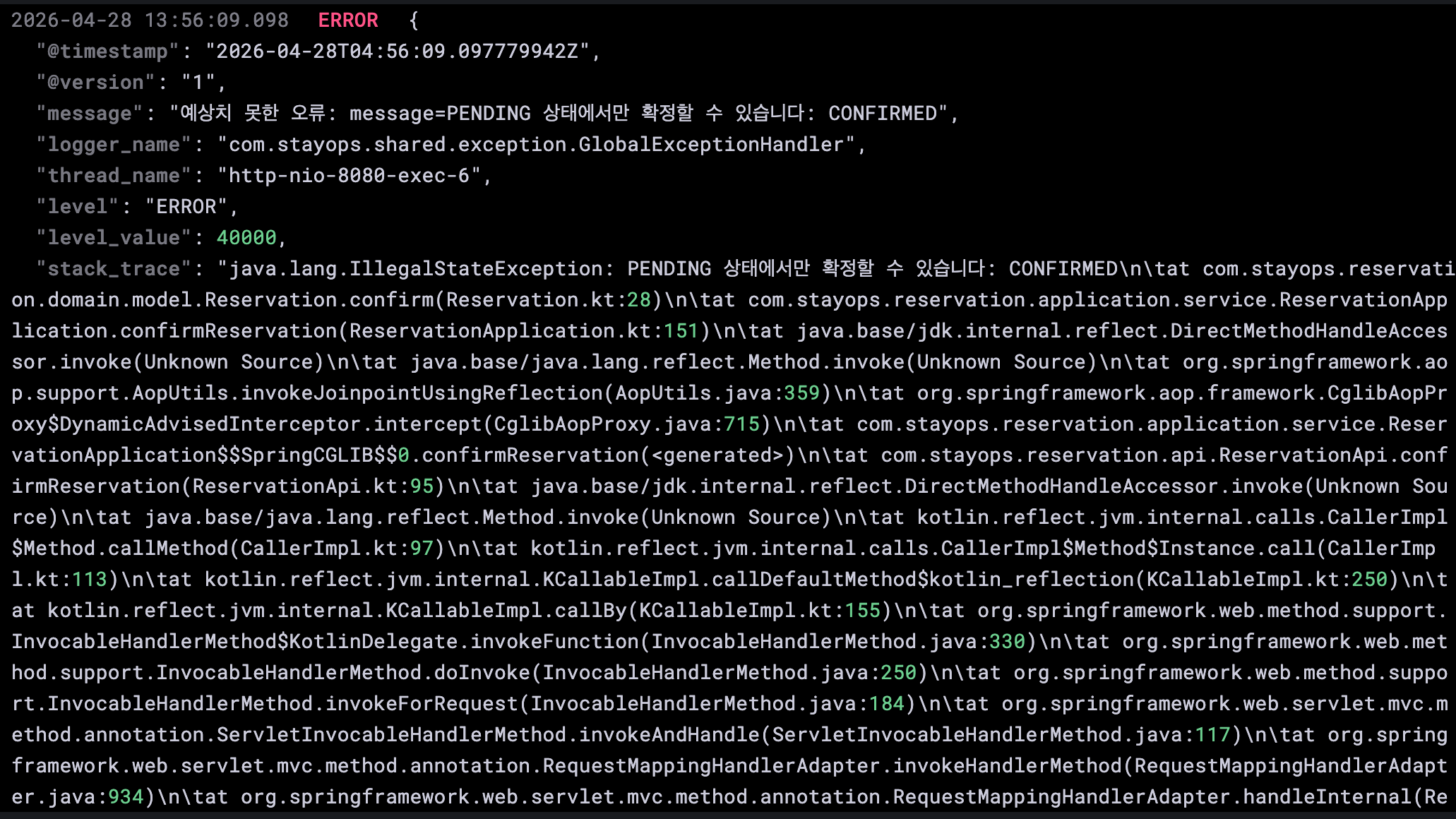
두 번째는 이미 CONFIRMED 상태인 예약에 대해 PMS 확정 API를 다시 호출했다는 뜻입니다.
도메인 모델은 PENDING -> CONFIRMED만 허용하므로 이 거절 자체는 정상인데, 테스트 시나리오 중에 같은 예약을 반복 확정했거나, 이미 확정된 예약을 확정 대상으로 다시 선택한 듯 합니다.
아마 smoke test에서는 비교적으로 적은 트래픽이었기 때문에 운이 좋게도 테스트 데이터 충돌이 없었나 봅니다.
그래서 예약 날짜 범위를 고정하고, PMS에서 confirm을 중복 실행하는 작업을 제거하도록 했습니다.
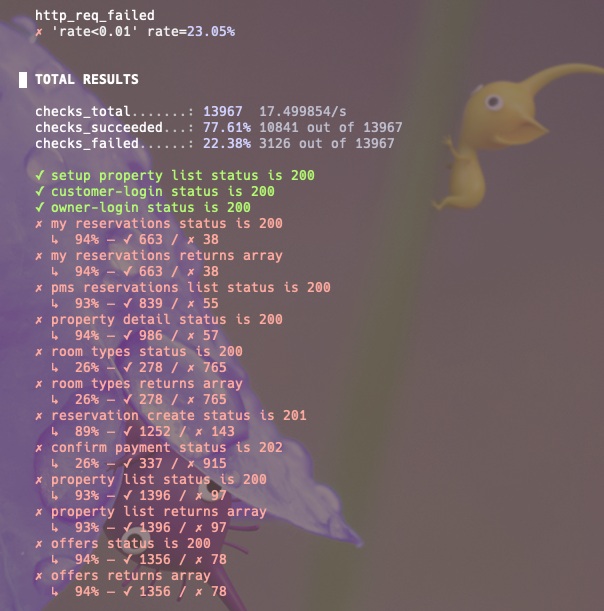
개선하고 실행해본 k6 부하테스트 결과입니다. Loki 로그를 확인해보니 여전히 같은 에러로 인해 몇 요청이 실패하고 있습니다.
여전히 예약 정보를 생성하는 조합의 갯수가 충분히 유니크해보이지 않아 보입니다.
그렇다고 비즈니스 로직에서 중복 예약 검증을 제거할 수는 없으니 어떻게 해야할까요?
예약 생성 데이터를 많이 넣는다고 해도 언젠가는 중복 가능성이 생길 것이고, 유효한 예약을 생성하지 못할 것입니다.
현재 문제는 예약 생성 시나리오가 고객, 객실 타입, 체크인/체크아웃 날짜를 랜덤으로 선택하면서 서버의 중복 기준인 조합(memberId + roomTypeId + checkIn + checkOut)을 다시 사용하여 중복 문제가 발생하는 것입니다.
- 고객: 보라피크민, 노란피크민
- 객실 타입: 스탠다드, 디럭스
- 체크인 후보: 2026-05-01, 2026-05-03, 2026-05-05
- 숙박 일수: 1박, 2박현재 같은 고객이 같은 객실 타입을 같은 날짜 범위로 다시 예약하려 하면 중복 예약으로 봅니다.
중복 판단 기준은 고객 + 객실 타입 + 체크인 날짜 + 체크아웃 날짜입니다.
그렇다면 만들 수 있는 서로 다른 예약 조합 수는 고객 2명 × 객실 타입 2개 × 체크인 날짜 3개 × 숙박 일수 2개 = 24개입니다.
기존에는 예약을 만들 때 고객, 객실 타입, 체크인 날짜, 숙박 일수를 랜덤으로 고릅니다.
- 예약 생성 1회차: 보라피크민 / 스탠다드 / 2026-05-01 체크인 / 2026-05-02 체크아웃
- 예약 생성 2회차: 노란피크민 / 디럭스 / 2026-05-03 체크인 / 2026-05-05 체크아웃
- 예약 생성 3회차: 보라피크민 / 스탠다드 / 2026-05-01 체크인 / 2026-05-02 체크아웃3회차는 1회차와 완전히 같은 예약으로 판단하고 409 DUPLICATE_RESERVATION을 반환합니다.
같은 고객이 같은 조건으로 예약 버튼을 두 번 누른 상황이 되어버린 것입니다.
이 문제를 막기 위해 예약 생성 조건을 무작위로 고르지 않고, 미리 정해진 순서대로 사용하도록 일종의 번호표를 사용하도록 변경했습니다.
- 예약 번호표 0: 보라피크민 / 스탠다드 / 2026-05-01 체크인 / 2026-05-02 체크아웃
- 예약 번호표 1: 보라피크민 / 스탠다드 / 2026-05-01 체크인 / 2026-05-03 체크아웃
- 예약 번호표 2: 보라피크민 / 스탠다드 / 2026-05-03 체크인 / 2026-05-04 체크아웃
- 예약 번호표 3: 보라피크민 / 스탠다드 / 2026-05-03 체크인 / 2026-05-05 체크아웃
- 예약 번호표 4: 보라피크민 / 스탠다드 / 2026-05-05 체크인 / 2026-05-06 체크아웃
- 예약 번호표 5: 보라피크민 / 스탠다드 / 2026-05-05 체크인 / 2026-05-07 체크아웃
...
- 예약 번호표 23: 노란피크민 / 디럭스 / 2026-05-05 체크인 / 2026-05-07 체크아웃이렇게 되면 예약 번호표 0부터 23까지는 같은 예약 조건이 다시 나오지 않습니다.
부하 테스트 시나리오는 예약 생성만 있는 것이 아니라 숙소 목록 조회, 객실/요금 조회, 내 예약 조회 같은 흐름도 섞여 있습니다.
첫 번째 실행: 숙소 목록 조회
두 번째 실행: 객실/요금 조회
세 번째 실행: 예약 생성
네 번째 실행: 내 예약 조회
다섯 번째 실행: 예약 생성이때 예약 번호표는 예약을 만들 때만 사용되며:
세 번째 실행의 예약 생성 -> 예약 번호표 0 사용
다섯 번째 실행의 예약 생성 -> 예약 번호표 1 사용숙소 목록 조회나 객실/요금 조회는 실제 예약을 만들지 않으므로 예약 번호표를 사용하지 않습니다. 그래서 조회 요청이 아무리 중간에 많이 섞여도 예약 가능한 조합을 낭비하지 않습니다.
다만 이 번호표 방식도 사용할 수 있는 조합 수를 넘으면 여전히 테스트 중간에 중복 예약이 발생할 수 있습니다.
// 예약 조합 수 계산
export function countUniqueReservationCombinations({
customerSessions,
bookableRoomTypes,
checkInOffsets,
nightsPool
}) {
return customerSessions.length * bookableRoomTypes.length *
checkInOffsets.length * nightsPool.length;
}
// capacity 검증
const requiredEndExclusive = sequenceOffset + requiredCreates;
if (requiredEndExclusive > capacity) {
throw new Error(
`Reservation combination capacity exhausted.
requiredEndExclusive=${requiredEndExclusive}, capacity=${capacity}.`
);
}
...이를 위해 사용 가능한 예약의 조합수를 계산하게 하고 setup 단계에서 capacity를 검증하도록 했습니다.
그래서 부하 테스트 전에 (시작 번호표 + 이번 테스트에 필요한 예약 생성 수) > 전체 번호표 수가 되면 테스트 시작 전에 실패하도록 만들고 필요한 예약 생성수가 되도록 조치를 취하게끔 만들었습니다.
중복 예약 문제를 해결했나 싶었는데 이번엔 Ngnix에서 오류가 발생했습니다.
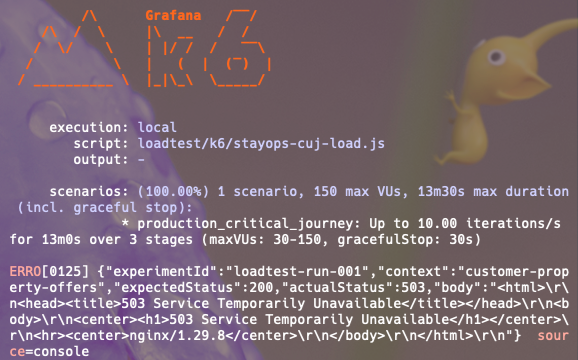
Ngnix는 각 서비스에 대한 요청 빈도를 제한하여 시스템 과부하를 방지하는 Rate limit을 제공하는데, K6를 실행하는 주체인 로컬 PC의 단일 IP요청이 계속 들어오기 때문에 접근 요청을 막은 듯 합니다.
그래서 일시적으로 ngnix 설정의 allow list를 k6 요청이 들어오는 IP를 허용하고 다시 진행했습니다.

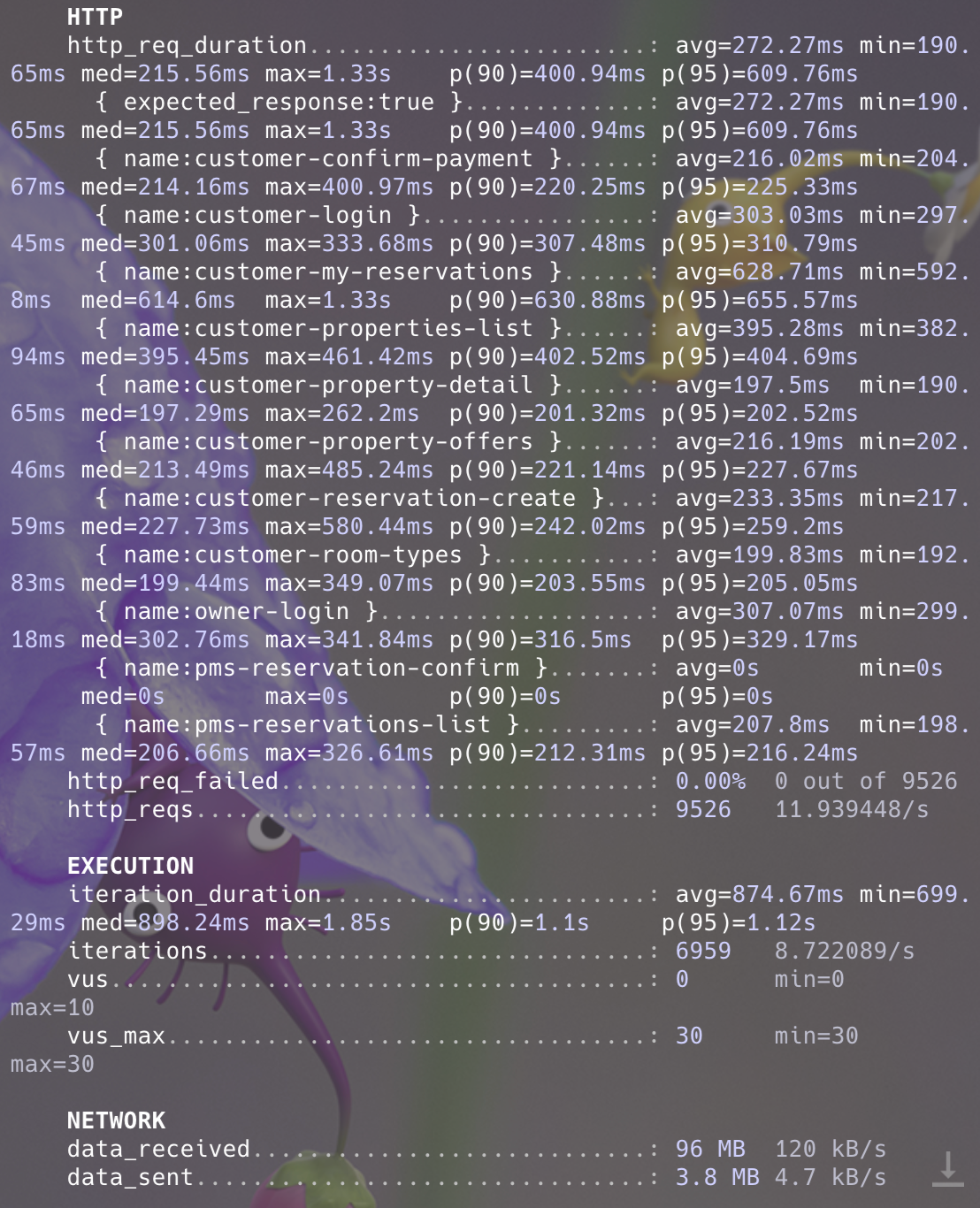
드디어 baseline test가 성공했습니다.
p95(100개 요청 중 95개가 해당 시간안에 끝났음을 의미) 지연율을 보면 200~650ms정도이고 실패율은 0으로 모든 요청을 처리했습니다.
메트릭을 살펴보니 하드웨어 성능문제도 아직까지는 없었습니다.
Strees test
Stress test는 일종의 내구성 테스트로 시스템이 임계치에 도달했을 때 서비스 중단점에서 동작하는지, 복구 가능성을 확인하는 테스트입니다.
MODE=stress \
LOADTEST_RUN_ID=run-001 \
CUJ_RATE=10 \
STRESS_RATE_MULTIPLIER=1.5 \
CUSTOMER_COUNT=30 \
OWNER_COUNT=10 \
k6 run stayops-cuj-load.jsbaseline test 통과 기준이었던 10CUJ/s의 150%인 15CUJ/s로 진행해보겠습니다.
그런데 한 18분쯤되서 로그가 우수수 하게 쏟아졌는데 서버 응답이 느려지면서 기존 VU가 요청을 못한 것 같군요.
free -h
total used free shared buff/cache available
Mem: 1.9Gi 1.9Gi 70Mi 1.8Mi 99Mi 34Mi
Swap: 0B 0B 0B이번엔 서버의 메모리가 병목이었습니다. 그래서 grafana도 동작하지 않았습니다.
결국 App 서버의 스펙을 t2.medium(2core, 4GIB)로 scale-up하고 stress test를 다시 진행하겠습니다.
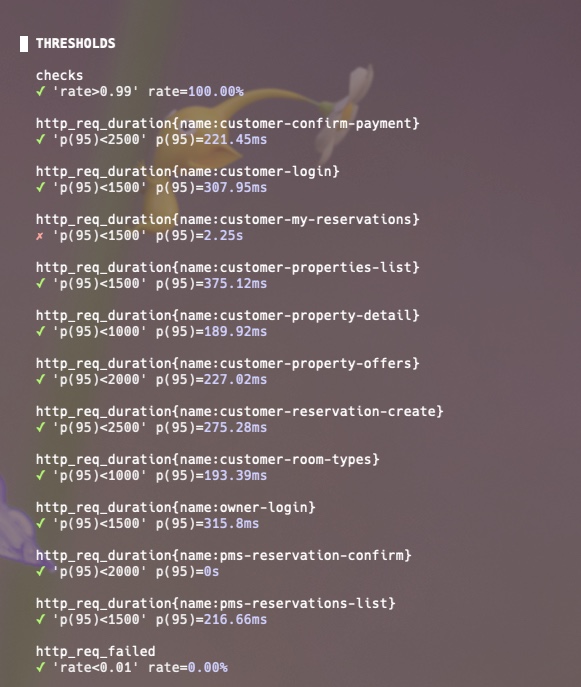
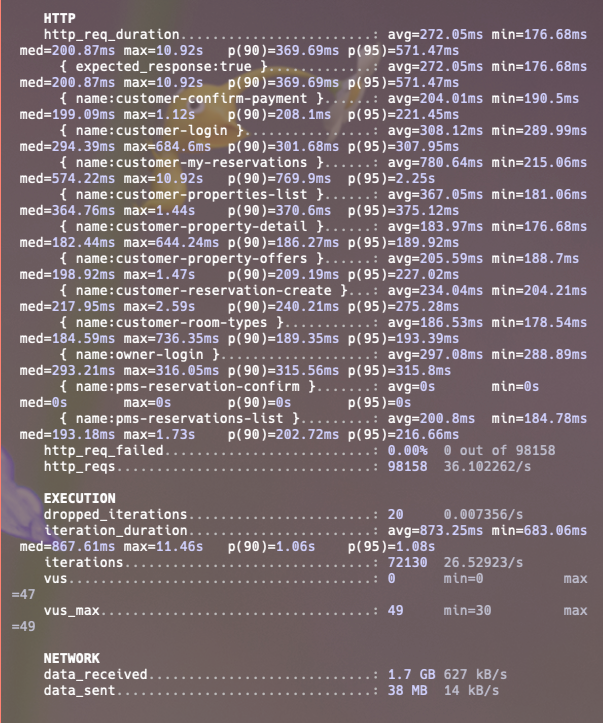
인스턴스 스펙을 올리고 진행한 첫 번째 stress test 결과입니다.
http_req_duration p95 = 571.47ms
p90 = 369.69ms
avg = 272.05ms요청 실패는 없었지만 현재 내 예약 목록 조회(customer-my-reservations)가 stress 부하가 돋보입니다.
대부분 API는 200~400ms대 p95인데, 내 예약 조회만 p95가 2.25초이고 특히 max=10.92s가 같이 보이므로 단순 평균 문제가 아니라 일부 요청에서 긴 tail latency가 발생했습니다.
메트릭을 확인해봤을 때 자원에서 생긴 병목은 아닌 듯 하여 애플리케이션 코드에서 원인을 살펴봤습니다.
그 중 문제가 의심되는 부분이 몇 개 있었는데:
// 문제 후보 1
@GetMapping
fun getMyReservations(): ResponseEntity<List<MyReservationResponse>> {
val member = customerAuthChecker.requireCustomer()
val reservations = customerReservationApplication.getMyReservations(member.id)
return ResponseEntity.ok(reservations.map { MyReservationResponse.from(it) })
}
...
// 문제 후보 2
@Transactional(readOnly = true)
fun getMyReservations(memberId: String): List<CustomerReservationReadResult> {
val reservations = reservationRepository.findByMemberId(memberId)
val paymentsByReservationId = reservationPaymentPort.findByMemberId(memberId)
.associateBy { it.reservationId }
return reservations.map { reservation ->
CustomerReservationReadResult(reservation, paymentsByReservationId[reservation.id])
}
} Pagenation 없이 ReservationResponse를 리스트 통째로 반환하여 예약 전체를 응답하고 있고, 조회에서 memberID 기준으로 조회하고 있지만 reservations.memberId에 인덱스가 걸려있지 않았습니다.
이렇게 되면 데이터가 늘어날수록 collection scan(RDB로 따지면 full scan)을 할 가능성이 높아지겠죠.
그렇다면 인덱스 추가와 페이지네이션 기능을 추가하고 이 API만 다시 stress test를 돌려보도록 하겠습니다.
// API 응답 구조 변경
@GetMapping
fun getMyReservations(
@RequestParam(defaultValue = "0") page: Int,
@RequestParam(defaultValue = "20") size: Int
): ResponseEntity<PagedMyReservationResponse>
// 복합 인덱스 추가 및 조회 개선
indexOps.createIndex(
CompoundIndexDefinition(
Document(mapOf("memberId" to 1, "createdAt" to -1))
)
)
val query = Query(Criteria.where("memberId").`is`(memberId))
val pageable = PageRequest.of(page, size, Sort.by(Sort.Direction.DESC,"createdAt"))
query.with(pageable)
val content = mongoTemplate.find(query, ReservationDocument::class.java) 전체 예약을 가져왔던 응답 구조를 Pagenation으로 변경했고, 같은 회원 안에서는 createdAt이 최신순으로 정렬되야하도록 했기 때문에 복합 인덱스(member_id, createAt)를 통해서 조회할 수 있도록 변경했습니다.
해당 API만 다시 부하 테스트를 다시 해봅시다.
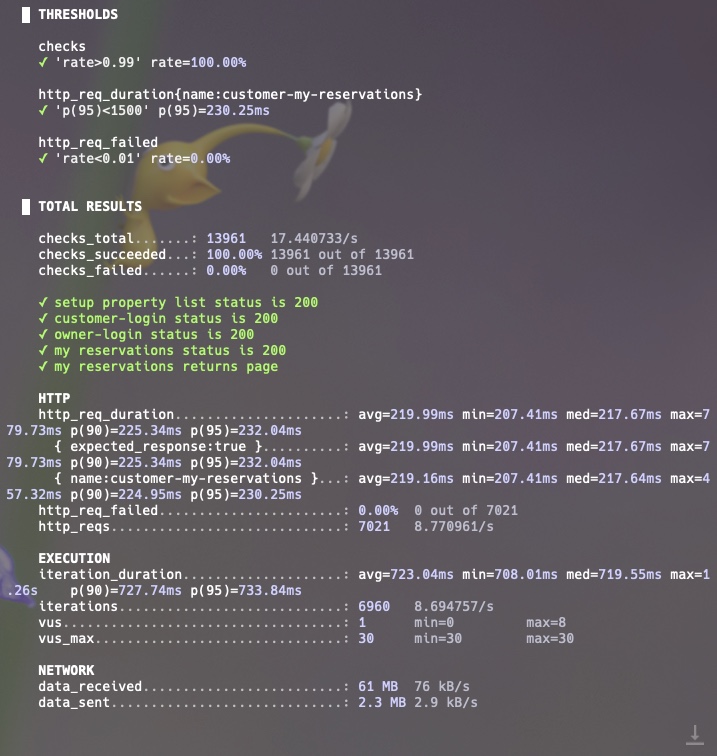
2.25초가 걸렸던 my reservation의 p95를 230ms로 개선했습니다. (사실 이걸 하려던게 아닌데..)
Breakpoint test
Breakpoint test는 시스템 한계점을 알아낸 뒤에 그 한계에 도달했을 때의 시스템 반응을 평가하는 방식입니다.
부하를 점진적으로 증가시키면서 높은 부하를 때려 실패 지점을 찾는데, 저희는 strees test에서 측정했던 CUJ 기준점부터 점진적으로 높이는 단계를 거치고, threshold에 걸리면 유예 시간(일단 2분 세팅)동안 지켜본 뒤에 부하 테스트를 멈추도록 세팅해놨습니다.
바로 멈추게 되면 순간적인 트래픽 흔들림(?)을 시스템 한계로 오판할 수 있을 것 같다고 판단하고 메트릭으로 추가적으로 확인을 해보려고 합니다.
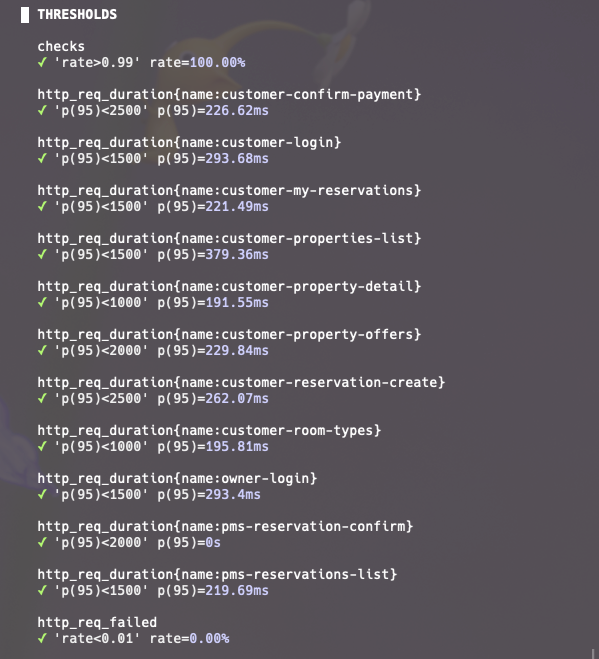
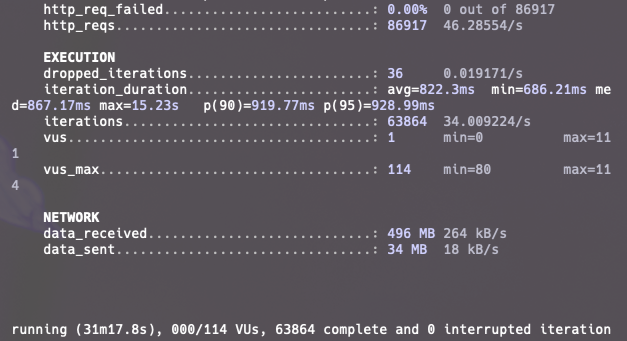
그런데? 실패할줄 알았는데 80CUJ/s 까지 HTTP 실패가 0건이고 주요 API의 p95 모두 기준이 통과했습니다.
80CUJ/s까지는 어떻게 버티는 것을 확인할 수 있었는데 아직 서버 한계를 측정하지 못했으니 CUJ를 80부터 점진적으로 다시 올려보겠습니다.
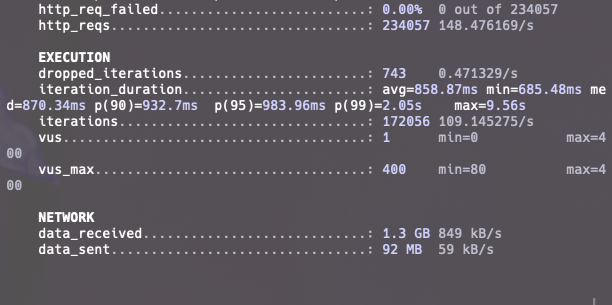
사실 80에서 간당간당했기 때문에 threshold 에러가 발생하면서 끝날 줄 알았는데 에러없이 테스트를 마쳤습니다.
약 100~110CUJ/s 이상의 요청도 처리했고, DB의 메모리나 CPU, 커넥션에도 큰 문제가 없었습니다.
다만 160 CUJ 목표는 k6 VU 부족(insufficient vu)으로 진행하지 못했습니다. VU는 가상 사용자를 의미하는데, 160CUJ/s는 초당 160개의 CUJ iteration을 시작하려는 목표 arrival rate입니다. VU는 그 CUJ를 실제로 실행하는 작업자의 역할을 하는 것이죠.
굳이 계산하자면 필요한 VU 수 ≈ 목표 CUJ/s × 평균 CUJ 수행 시간(초)인데:
160 CUJ/s × 평균 0.5초 = 약 80 VU 필요
160 CUJ/s × 평균 0.9초 = 약 144 VU 필요
160 CUJ/s × 평균 2.5초 = 약 400 VU 필요우리가 목표했던 CUJ에 도달하기에는 VU가 턱없이 부족했던 것이죠.
그래서 목표 CUJ에 도달할 수 있도록 VU 30에서 min VU를 80으로 세팅했습니다.
다시 breakpoint 테스트를 진행해봅시다.
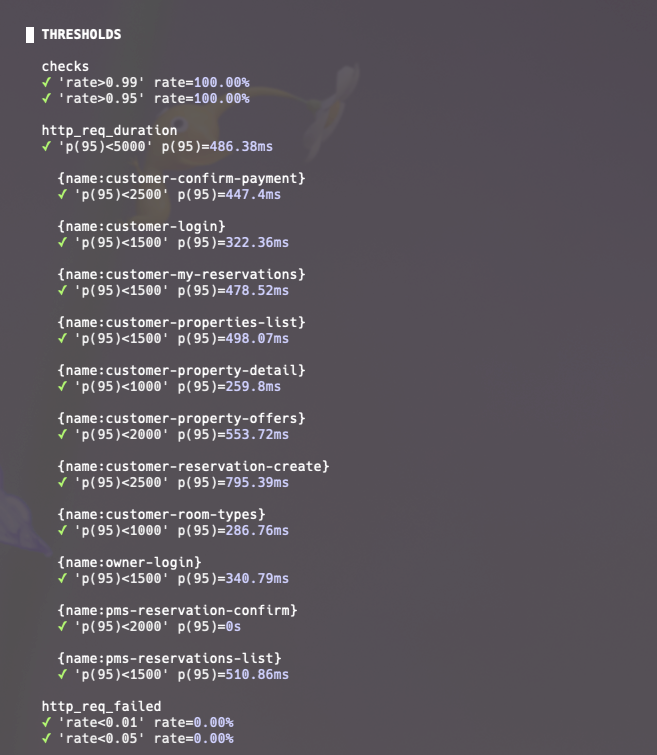
그런데 이번에도 fail없이 모두 성공했습니다. break point를 찾기에는 CUJ를 너무 낮게 선정한 듯합니다. CUJ를 좀 더 높여보겠습니다.
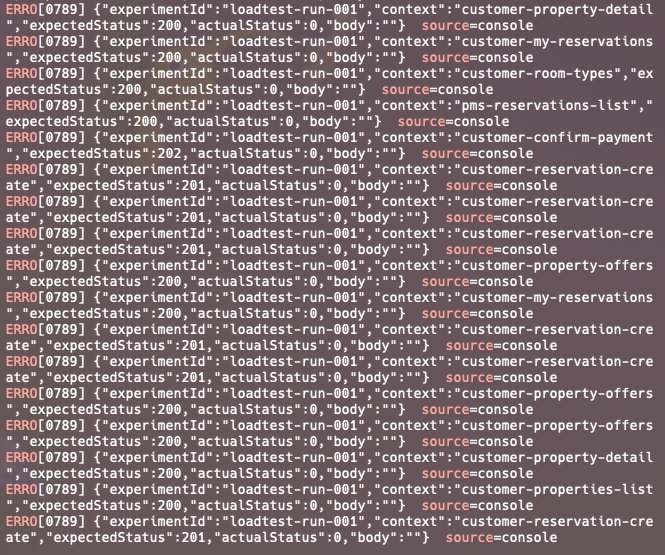
테스트 시작한지 11분(260 CUJ/s 부근)부터 에러가 발생해서 중단하고 k6의 결과를 살펴봤습니다.
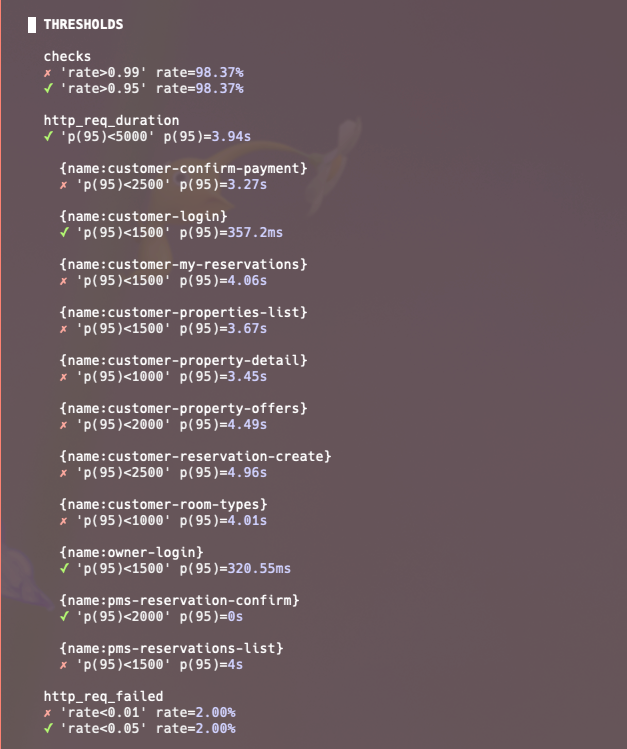
전반적으로 지연율이 늘어났고 요청 실패도 발생했습니다.
메트릭을 보고 원인을 찾아봅시다:
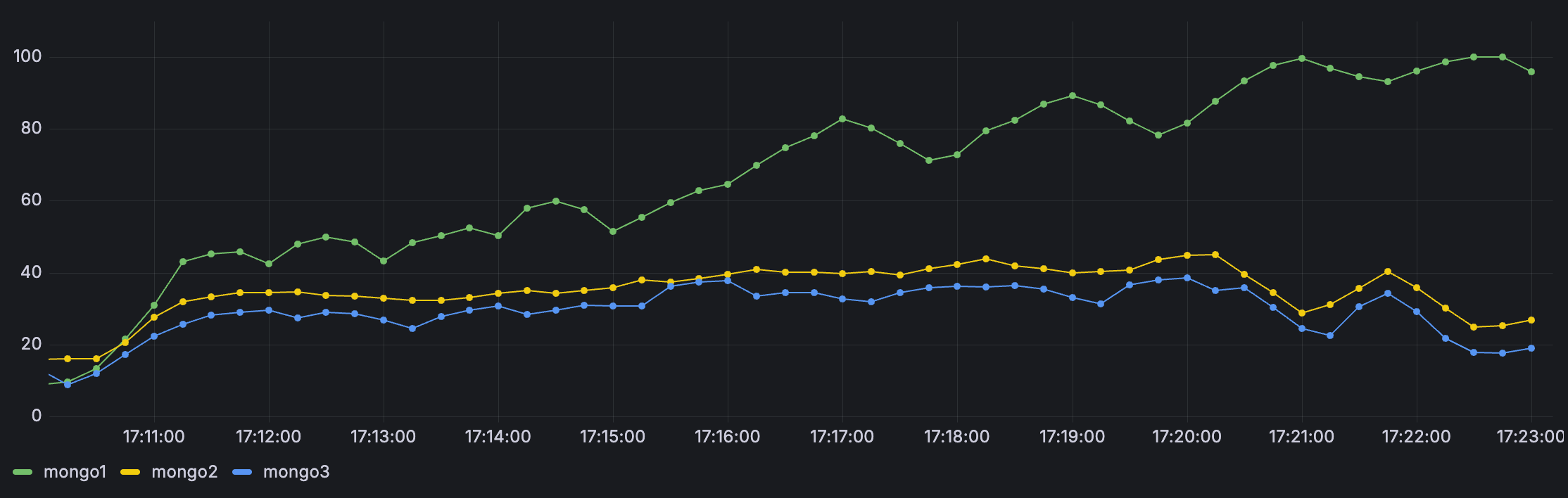
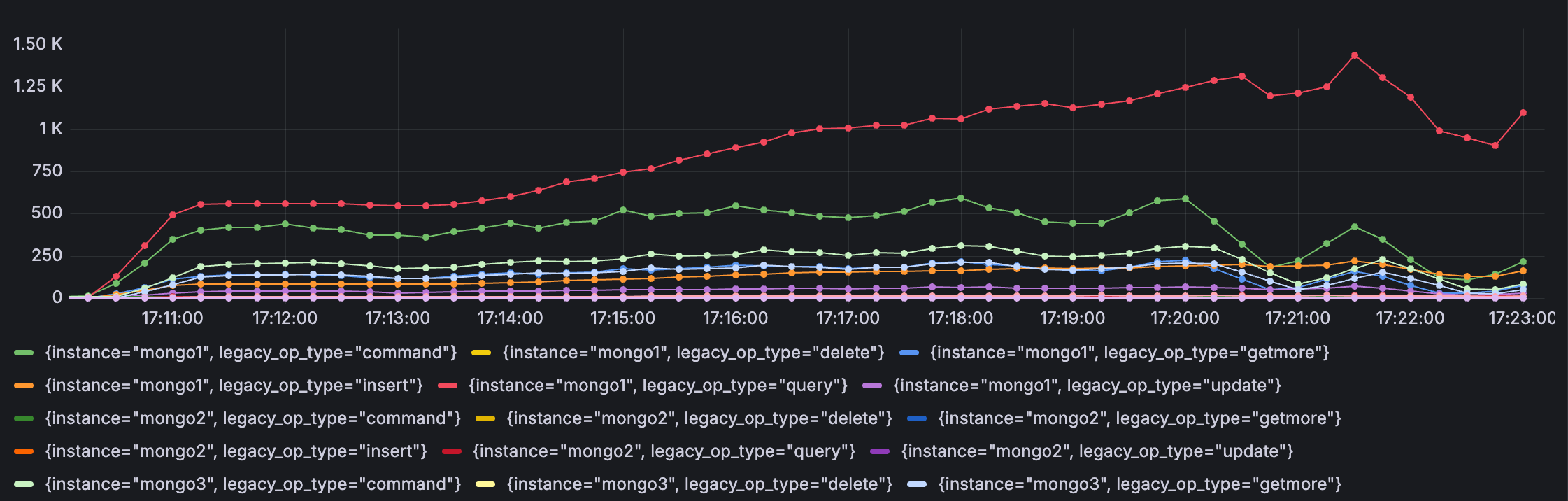
app 서버의 자원은 크게 문제는 없었고 대부분 primary db인 mongodb1에서 문제가 발생했습니다.
테스트 시작 11분 뒤인 ‘17:21’부터 primary db의 CPU 사용률과 mongo operaiton rate가 급증하는 것을 확인할 수 있었는데, primary db에 예약 생성과 결제 확정 write path가 흔들리고 조회 API 전반까지 지연율이 같이 올라간 듯합니다.
결과적으로 현재 DB 스펙으로는:
- 260 CUJ/s 구간에서 Mongo primary CPU와 query/write 처리량이 포화에 가까워지고,
- App request thread가 Mongo 응답을 기다리며 timed-waiting 증가하며
- 그 결과 reservation-create/confirm-payment 중심으로 latency와 EOF가 발생한다라고 결론내릴 수 있을 것 같네요.
이제 260CUJ/s를 break point 후보로 보고 failover가 의도대로 동작하는지 테스트 해보겠습니다.
failover가 의도한대로 작동할까?
현재 primary db인 mongo1에 260CUJ/s에서 병목이 생기는 것을 확인했습니다.
break-point에서 알아본 한계치 이상의 부하를 가해서 컨테이너를 다운시켜서 heart-beat를 보내지 못하게 만들고 failover를 발생시키려고 했지만 failover 과정이 동작하는지 확인하기 위함이기 때문에, 안정적인 서버 상태를 유지할 수 있는 220CUJ/s까지 도달한 뒤 warm-up이 어느정도 마무리 된 11분쯤에 명시적으로 election을 일으키겠습니다.
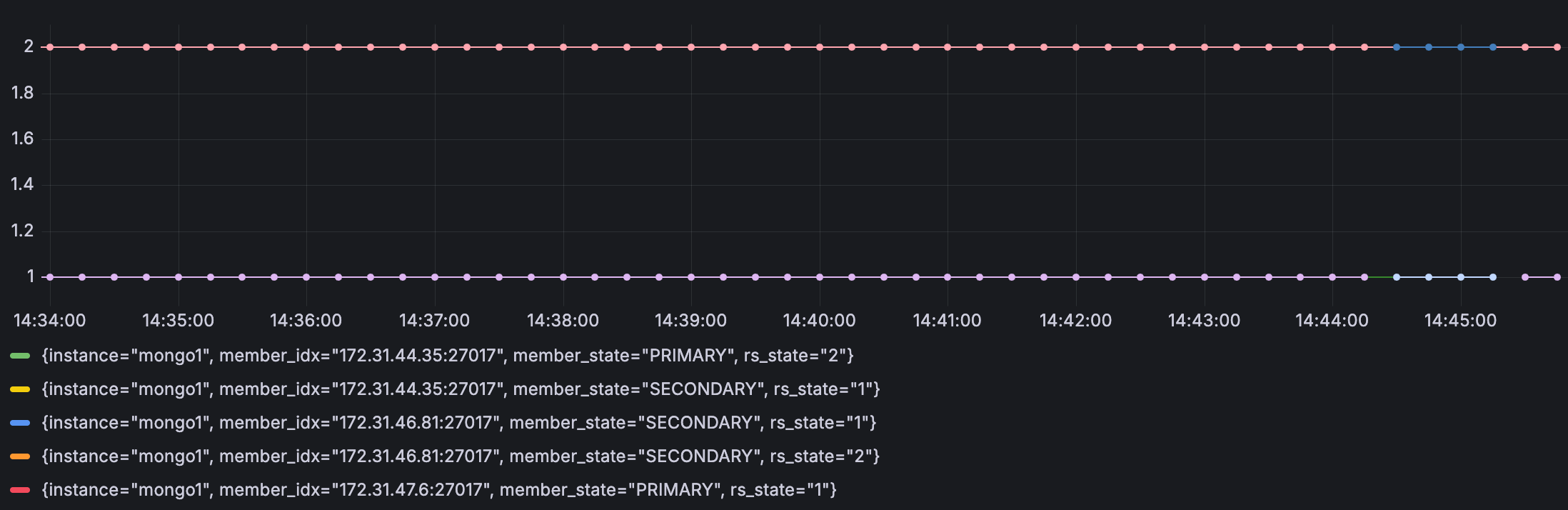
Replica set state를 살펴보았는데 primary replica set을 다운시킨 시점(44-45분 사이)부터 mongo1이 Secondary로 내려가고 mongo2가 primary로 승격했습니다.
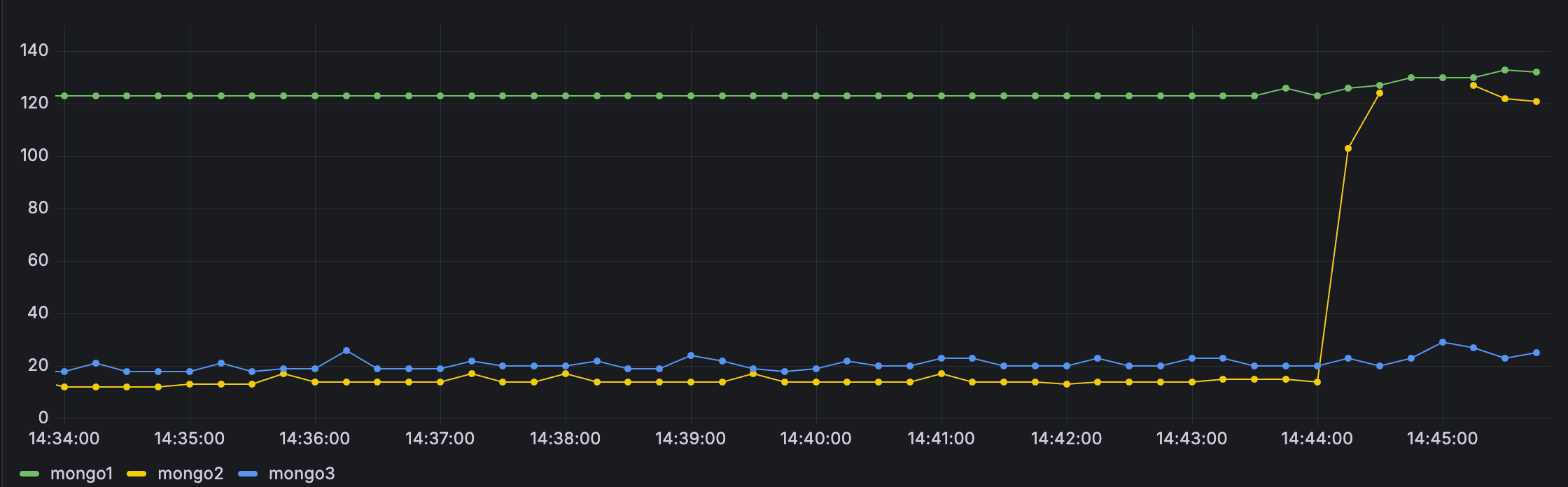
mongodb의 connection 수를 확인해보면 mongo2의 connection이 급증하면서 drvier가 재연결을 했음을 확인할 수 있었고 복구에는 1분 정도 소요되었네요.
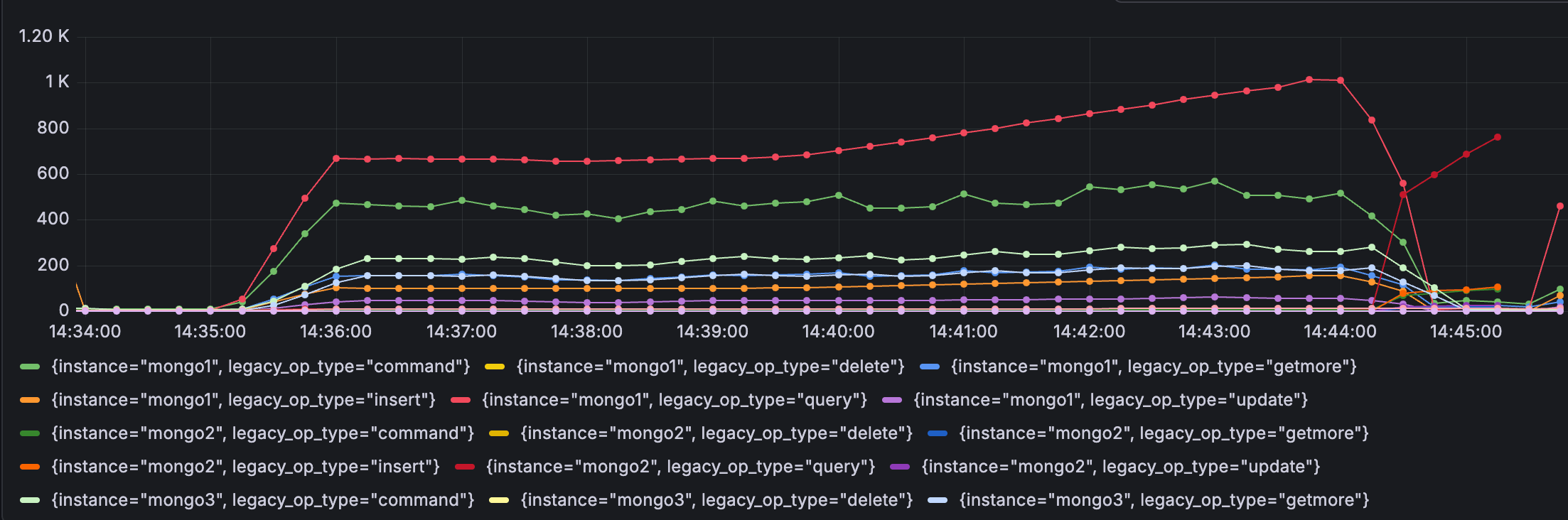
primary로 선정된 mongo2가 App의 읽기/쓰기 요청을 받기 시작하여 operation rate에서 확인할 수 있었습니다.
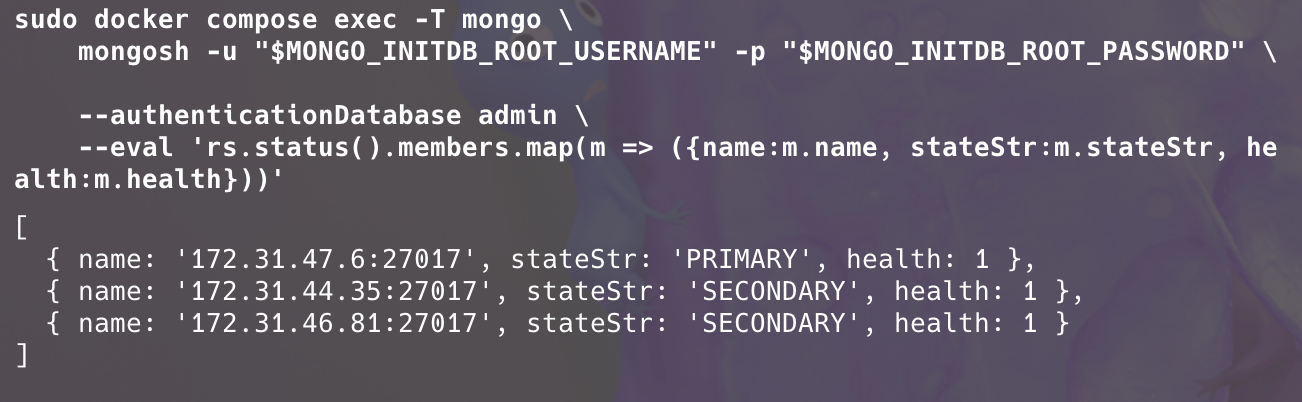
replica set은 primary의 쓰기 작업을 oplog에 기록하고 secondary가 oplog를 가져와 적용하는데 이 때 뒤처진 시간을 lag이라고 합니다.
secondary가 primary db의 변경 사항을 얼마나 늦게 따라오고 있는지 Replication lag을 확인해보면
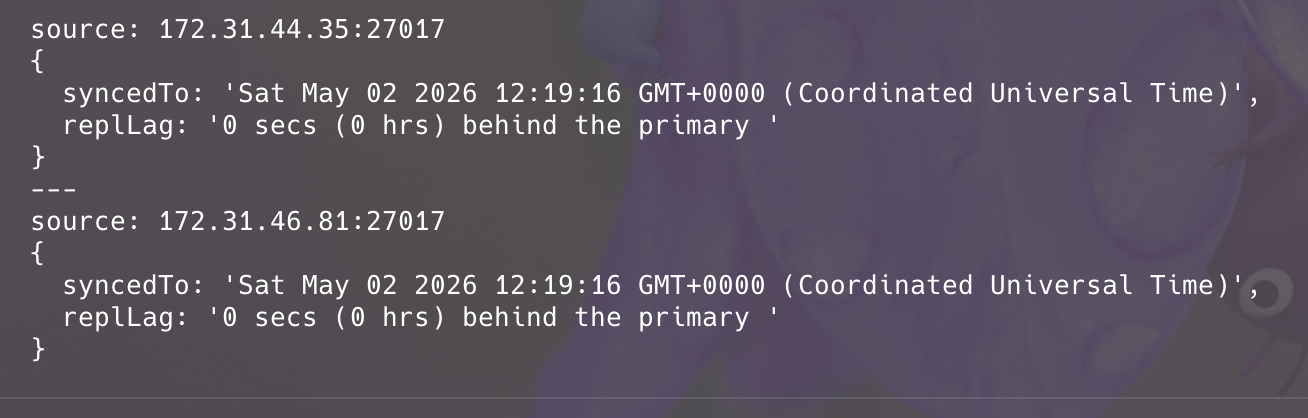
복제 지연없이 데이터 동기화까지 마쳤습니다.
복구 중에 어떤 작업을 해야할까?
failover 작업은 1분 내외로 끝났지만 그 사이에 사용자들은 애플리케이션을 정상적으로 이용하지 못할 것입니다. 이는 failover 뿐만 아니라 App 서버나 DB의 자원 부족 혹은 네트워크 오류로 인한 문제가 발생했을 때도 일어날 수 있는 일입니다.
장애는 피할 수 없는 상황이니 장애가 생긴 동안에 할 수 있는 조치를 해야할텐데 무엇을 해야할까요? 이에 대해 고민해본 과정을 적어봤습니다.
Timtout 설정
Timeout은 어떤 프로그램이 특정한 시간 내에 성공적으로 수행되지 않으면 진행을 중단시키는 메커니즘을 의미합니다.
먼저 클라이언트와 서버 관점에서 Timeout을 생각해봤는데:
클라이언트에서 timeout이 없다면 사용자가 응답없는 화면을 계속 기다립니다. 네트워크 문제나 failover 중에 App 서버가 늦게 응답하게 되면 사용자 경험을 해칠 수 있다고 생각했습니다.
이를 위해 Axios의 timeout 세팅을 8초로 먼저 설정했습니다.
const REQUEST_TIMEOUT_MS = 8_000
client.defaults.timeout = REQUEST_TIMEOUT_MS너무 짧으면 서버가 오류 응답을 내려주기 전에 클라이언트 측에서 먼저 끊을 수도 있다고 판단했습니다. (너무 긴가 싶기도 하고..)
응답이 8초 안에 온다면 정상 처리를 하고, 8초 내 응답이 없다면 Axios가 요청을 실패 처리하고 timeout 에러를 사용자 메시지로 변환하여 표시하도록 했습니다.
다음은 Server의 timeout입니다.
현재 서버는 Spring WebMVC(동기식) 기반입니다. 때문에 요청 하나가 Tomcat의 worker thread 하나를 점유하는 형태인데, 이렇게 되면 새로운 요청을 처리할 수 있는 thread가 묶여있기 때문에 새로운 요청이 thread를 사용할 수 없는 일이 생길 수 있습니다.
timoeout을 설정한다면 DB의 응답을 기다리지 않고 시간이 만료되면 자원을 반환하면서 새로운 요청을 처리할 수 있는 thread가 작업할 수 있게 되겠죠.
// yml
stayops:
mongodb:
timeout:
server-selection-timeout: 5s
connect-timeout: 2s
read-timeout: 5s
// MongoDriver 설정
@Bean
fun mongoClientTimeoutCustomizer(
properties: MongoTimeoutProperties
): MongoClientSettingsBuilderCustomizer {
return MongoClientSettingsBuilderCustomizer { builder ->
builder.applyToClusterSettings {
it.serverSelectionTimeout(
properties.serverSelectionTimeout.toMillis(),
TimeUnit.MILLISECONDS
)
}
builder.applyToSocketSettings {
it.connectTimeout(
properties.connectTimeout.toMillis(),
TimeUnit.MILLISECONDS
).readTimeout(
properties.readTimeout.toMillis(),
TimeUnit.MILLISECONDS
)
}
}
}보면 timeout의 종류가 3개인데 확인할 수 있는데 무슨 차이일까요?
- server-selection-timeout
server-selection-timeout은 DB driver가 요청을 보낼 MongoDB 서버를 찾는 시간입니다.
App에서 DB에게 요청을 시도하면 driver가 사용 가능한 DB 서버를 탐색하는데, 이 때 설정한 5초 안에 찾지 못하면 TimeoutException을 발생시킵니다.
예를 들어 failover, election 작업 중에 새로운 primary가 선출되지 않았을 때 timeout을 발생할 수 있을 것입니다.
- connect-timeout
connect-timeout은 MongoDB 서버와 새 socket connection을 맺는 시간을 설정하는 timeout 입니다.
MongoDB driver가 통신하고자 하는 mongoDB에 연결 시도를 하게되면 TCP Connection을 생성하게 되는데 이 때 설정한 시간 안에 연결이 실패하면 connect timeout이 발생합니다.
- read-timeout
read-timeout은 연결된 MongoDB socket으로 요청을 보낸 뒤, 응답을 읽는 시간을 설정하는 timeout입니다.
TCP 통신 성공 후에 connection이 되어있는 상태에서 DB의 응답을 읽으려고 기다리는데 설정한 시간 내에 응답을 받지 못하면 timeout이 발생합니다.
이렇게 사용자 경험과 서버 자원을 고려하여 timeout 설정을 고려하게 되었습니다.
예외 응답처리 개선
원래 MongoDB에서 발생한 일시적인 장애는 모두 500 INTERNAL_ERROR로 처리했었는데 원인 분석을 위해 다음과 같이 개선했습니다.
// GlobalExceptionHandler.kt
private fun Throwable.isTransientMongoFailure(): Boolean =
generateSequence(this) { it.cause }
.filterIsInstance<MongoException>()
.any { mongoException ->
mongoException is MongoTimeoutException ||
mongoException is MongoSocketException ||
mongoException is MongoNotPrimaryException ||
mongoException is MongoNodeIsRecoveringException ||
mongoException.hasErrorLabel(MongoException.TRANSIENT_TRANSACTION_ERROR_LABEL) ||
mongoException.hasErrorLabel(MongoException.UNKNOWN_TRANSACTION_COMMIT_RESULT_LABEL)
}
...
if (ex.isTransientMongoFailure()) {
return ResponseEntity.status(HttpStatus.SERVICE_UNAVAILABLE)
.header(HttpHeaders.RETRY_AFTER, retryAfterSeconds)
.body(
ErrorResponse(
code = "TEMPORARILY_UNAVAILABLE",
message = "일시적으로 서비스를 사용할 수 없습니다. 잠
시 후 다시 시도해 주세요.",
timestamp = Instant.now()
)
)
}
...MongoDB에서 발생한 에러 요청을 별도로 분리하여 확인할 수 있도록하고 MongoDB에서 일어난 장애를 확인할 수 있도록 변경했습니다.
이렇게 되면 장애 발생 시 로그를 보고 MongoDB에서 발생한 문제임을 확인하고 조치를 취할 수 있을 것입니다.
요청 재시도
failover나 네트워크 문제같은 상황은 영구적인 장애가 아니기 때문에 재시도 요청을 해볼 수 있을 것 같습니다.
첫 요청: MongoDB failover 중 -> 503
1초 대기
재시도: 새 primary 선택 완료 -> 200 OK이때 첫 요청은 실패하지만 몇 초 뒤에 같은 조회 요청을 다시 보내면 복구가 되어서 성공할 가능성이 있겠죠.
이렇게 되면 사용자가 직접 새로고침하거나 다시 요청을 하지 않아도 되고, 짧은 네트워크 오류, timeout, failover 중 읽기 실패를 완화(?)할 수 있습니다.
또한 서버 내부에서 스레드를 붙잡고 재시도하지 않고, 실패 응답 후 클라이언트가 새 요청을 보내므로 서버 자원의 점유를 줄일 수 있을 것입니다.
// recovery.ts
const REQUEST_TIMEOUT_MS = 8_000 // 요청 timeout
const MAX_SAFE_RETRY_COUNT = 1 // 자동 재시도: 최대 1회
const DEFAULT_RETRY_DELAY_MS = 1_000 // 기본 재시도 대기: 1초
const MAX_RETRY_AFTER_MS = 3_000 // Retry-After 최대 반영: 3초
const safeRetryMethods = new Set(['get', 'head', 'options']) // 재시도 허용 http 메서드
const retryableStatusCodes = new Set([408, 429, 502, 503, 504]) // 재시도 허용 상태 코드
client.interceptors.response.use(undefined, async (error:AxiosError) => {
const config = error.config as RetryableRequestConfig | undefined
if (!config || !shouldRetry(error, config)) {
return Promise.reject(withApiErrorMessage(error))
}
config.__safeRetryCount = (config.__safeRetryCount ?? 0) + 1
await wait(resolveRetryDelay(error))
return client.request(config)
})
...API 요청이 실패하면 Axios interceptor로 진입하고 재시도 가능한 요청인지 검사한 뒤에 불가능하면 에러를 반환하고, 가능하면 재시도 횟수 +1을 한 뒤 Retry-After 또는 기본 1초만큼 대기한 뒤에 같은 요청을 하도록 했습니다.
HTTP 허용 메서드는 멱등한 메서드에 한해서 진행했는데 요청을 여러번 보내도 상태가 달라지지 않기 때문입니다.
‘그렇다고 멱등하지 않은 메서드를 재시도하면 안되나?‘라는 생각을 해봤는데 중복 실행을 막거나 복구할 수 있는 장치가 있으면 가능한데, 요청을 실패한 채로 두었을 때의 비용이 더 커보이진 않아서 상태를 바꾸지 않는 멱등한 작업만 하도록 했습니다.
배운점
- 인프라 세팅은 귀찮다
부하 테스트 자체는 그렇게 오래걸리지 않았는데 각 인스턴스에 Docker container 세팅 및 여러 부차적인 설정 작업때문에 시간이 많이 소요되었습니다.
왜 돈주고 ECS같은 관리형 서비스나 Cluster를 왜 쓰는지 필요성에 대해 느낄 수 있었습니다.
그런데 서버리스 툴은 내부 동작을 다 추상화해버리기 때문에 공부하기에는 우직하게(?) 인스턴스 생성하고 컨테이너를 두는 방법이 더 좋은 것 같기도..
- 로그와 메트릭의 중요성
k6의 부하 테스트 결과로만 추정할 수 있는 원인이 한정되었지만, 로그를 남겨놓아서 문제 원인을 파악하는데 많은 도움을 받았습니다.
다만 로그를 남기는 것이 생각보다 자원이 드는 작업이기 때문에 정말 필요한 로그가 무엇인지 정답이 없는 문제를 확립하기 위해 더 경험해봐야겠습니다.
맺음
꽤 긴 작업이었는데 다 마치니 뿌듯하군요. 잘못된 내용이 있다면 언제나 피드백 환영입니다.
읽어주셔서 감사합니다.